|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Notes de cours, aide-mémoire
Informatique et technologies de l'information. Aide-mémoire : brièvement, le plus important
Annuaire / Notes de cours, aide-mémoire table des matières
1. Informatique. Informations Représentation et traitement / information. Systèmes de numération L'informatique est engagée dans une représentation formalisée des objets et des structures de leurs relations dans divers domaines de la science, de la technologie et de la production. Divers outils formels sont utilisés pour modéliser des objets et des phénomènes, tels que des formules logiques, des structures de données, des langages de programmation, etc. En informatique, un concept aussi fondamental que l'information a plusieurs significations : 1) présentation formelle des formes externes d'information ; 2) signification abstraite de l'information, son contenu interne, sa sémantique ; 3) relation de l'information au monde réel. Mais, en règle générale, l'information est comprise comme sa signification abstraite - la sémantique. Si nous voulons échanger des informations, nous avons besoin d'opinions cohérentes afin que l'exactitude de l'interprétation ne soit pas violée. Pour ce faire, l'interprétation de la représentation de l'information est identifiée à certaines structures mathématiques. Dans ce cas, le traitement de l'information peut être effectué par des méthodes mathématiques rigoureuses. L'une des descriptions mathématiques de l'information est sa représentation en fonction y = f(x,t) où t est le temps, x est un point dans un champ où la valeur de y est mesurée. En fonction des paramètres de fonction x et t, les informations peuvent être classées. Si les paramètres sont des grandeurs scalaires qui prennent une série continue de valeurs, alors l'information ainsi obtenue est dite continue (ou analogique). Si les paramètres reçoivent un certain pas de changement, alors l'information est dite discrète. Les informations discrètes sont considérées comme universelles. L'information discrète est généralement identifiée à l'information numérique, qui est un cas particulier d'information symbolique de représentation alphabétique. Un alphabet est un ensemble fini de symboles de toute nature. Très souvent en informatique, une situation se présente lorsque les caractères d'un alphabet doivent être représentés par les caractères d'un autre, c'est-à-dire qu'une opération de codage doit être effectuée. Comme l'a montré la pratique, l'alphabet le plus simple qui vous permet d'encoder d'autres alphabets est binaire, composé de deux caractères, qui sont généralement désignés par 0 et 1. En utilisant n caractères de l'alphabet binaire, vous pouvez encoder 2n caractères, et cela suffit pour coder n'importe quel alphabet. La valeur qui peut être représentée par un symbole de l'alphabet binaire est appelée unité minimale d'information ou bit. Séquence de 8 bits - octets. Un alphabet contenant 256 séquences différentes de 8 bits est appelé un alphabet d'octets. Un système de numération est un ensemble de règles permettant de nommer et d'écrire des nombres. Il existe des systèmes de numération positionnels et non positionnels. Le système de numération est appelé positionnel si la valeur du chiffre du nombre dépend de l'emplacement du chiffre dans le nombre. Sinon, il est dit non positionnel. La valeur d'un nombre est déterminée par la position de ces chiffres dans le nombre. 2. Représentation des nombres dans un ordinateur. Concept formalisé d'un algorithme Les processeurs 32 bits peuvent fonctionner avec jusqu'à 232-1 RAM et les adresses peuvent être écrites dans la plage 00000000 - FFFFFFFF. Cependant, en mode réel, le processeur fonctionne avec une mémoire allant jusqu'à 220-1 et les adresses se situent dans la plage 00000 - FFFFF. Les octets de mémoire peuvent être combinés dans des champs de longueur fixe et variable. Un mot est un champ de longueur fixe composé de 2 octets, un mot double est un champ de 4 octets. Les adresses de champ peuvent être paires ou impaires, les adresses paires exécutant les opérations plus rapidement. Les nombres à virgule fixe sont représentés dans les ordinateurs sous forme de nombres binaires entiers et leur taille peut être de 1, 2 ou 4 octets. Les nombres binaires entiers sont représentés en complément à deux. Le code supplémentaire d'un nombre positif est égal au nombre lui-même, et le code supplémentaire d'un nombre négatif peut être obtenu à l'aide de la formule suivante : x = 10n - \x\, où n est la profondeur de bits du nombre. Dans le système de numération binaire, un code supplémentaire est obtenu en inversant les bits, c'est-à-dire en remplaçant les unités par des zéros et vice versa, et en ajoutant un au bit le moins significatif. Le nombre de bits de la mantisse détermine la précision de la représentation des nombres, le nombre de bits d'ordre machine détermine la plage de représentation des nombres à virgule flottante. Concept formalisé d'un algorithme Un algorithme ne peut exister que si, en même temps, un objet mathématique existe. Le concept formalisé d'algorithme est lié au concept de fonctions récursives, algorithmes de Markov normaux, machines de Turing. En mathématiques, une fonction est dite à valeur unique si, pour tout ensemble d'arguments, il existe une loi par laquelle la valeur unique de la fonction est déterminée. Un algorithme peut agir comme une telle loi ; dans ce cas la fonction est dite calculable. Les fonctions récursives sont une sous-classe de fonctions calculables, et les algorithmes qui définissent les calculs sont appelés algorithmes de fonctions récursives compagnons. Premièrement, les fonctions récursives de base sont fixes, pour lesquelles l'algorithme d'accompagnement est trivial, sans ambiguïté ; puis trois règles sont introduites - les opérateurs de substitution, de récursivité et de minimisation, à l'aide desquels des fonctions récursives plus complexes sont obtenues sur la base de fonctions de base. Les fonctions de base et les algorithmes qui les accompagnent peuvent être : 1) une fonction de n variables indépendantes, identiquement égale à zéro. Ensuite, si le signe de la fonction est φn, alors quel que soit le nombre d'arguments, la valeur de la fonction doit être égale à zéro ; 2) la fonction identité de n variables indépendantes de la forme Ψ ni. Alors, si le signe de la fonction est Ψ ni, alors la valeur de la fonction doit être prise comme la valeur du i-ème argument, en comptant de gauche à droite ; 3) λ-fonction d'un argument indépendant. Ensuite, si le signe de la fonction est λ, alors la valeur de la fonction doit être prise comme la valeur suivant la valeur de l'argument. 3. Introduction au langage Pascal Les symboles de base de la langue - lettres, chiffres et caractères spéciaux - constituent son alphabet. Le langage Pascal comprend l'ensemble de symboles de base suivant : 1) 26 lettres latines minuscules et 26 lettres latines majuscules : 2) _ (trait de soulignement); 3) 10 chiffres : 0 1 2 3 4 5 6 7 8 9 ; 4) signes d'opérations : + - O / = <> < > <= >= := @; 5) délimiteurs :., ( ) [ ] (..) { } (* *).. : ; 6) spécificateurs : ^ # $ ; 7) mots de service (réservés) : ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FONCTION, GOTO, IF, IMPLEMENTATION, IN, INDEX, HERITED, INLINE, INTERFACE, INTERRUPT, LABEL, LIBRARY, MOD, NAME, NIL, NEAR, NOT, OBJECT, OF, OR, PACKED, PRIVATE, PROCEDURE, PROGRAMMER, PUBLIC, ENREGISTRER, RÉPÉTER, RÉSIDENT, RÉGLER, SHL, SHR, CHAÎNE, PUIS, À, TYPE, UNITÉ, JUSQU'À, UTILISATIONS, VAR, VIRTUEL, PENDANT, AVEC, XOR. En plus de ceux répertoriés, le jeu de caractères de base comprend un espace. Il existe une règle en Pascal : le type est explicitement spécifié dans la déclaration d'une variable ou d'une fonction qui précède son utilisation. Le concept de type Pascal a les principales propriétés suivantes : 1) tout type de données définit un ensemble de valeurs auquel appartient une constante, qu'une variable ou une expression peut prendre, ou qu'une opération ou une fonction peut produire ; 2) le type de valeur donné par une constante, une variable ou une expression peut être déterminé par leur forme ou leur description ; 3) chaque opération ou fonction nécessite des arguments de type fixe et produit un résultat de type fixe. Il existe des types de données scalaires et structurés en Pascal. Les types scalaires incluent les types standard et les types définis par l'utilisateur. Les types standard incluent les types entier, réel, caractère, booléen et adresse. Les types entiers définissent des constantes, des variables et des fonctions dont les valeurs sont réalisées par l'ensemble des entiers autorisés dans un ordinateur donné. Pascal a la priorité d'opérateur suivante :
1) calculs entre parenthèses ; 2) calcul des valeurs de fonction ; 3) opérations unaires ; 4) opérations * / mod div et; 5) opérations + - ou xor ; 6) opérations de relation = <> < > <= >=. 4. Procédures et fonctions standard Fonctions arithmétiques 1.Fonction Abs(X); renvoie la valeur absolue du paramètre. 2. Fonction ArcTan(X : Etendu) : Etendu ; renvoie l'arc tangente de l'argument. 3. Fonction Exp(X : Réel) : Réel ; renvoie l'exposant. 4.Frac(X : Réel) : Réel ; renvoie la partie fractionnaire de l'argument. 5. Fonction Int(X : Réel) : Réel ; renvoie la partie entière de l'argument. 6. Fonction Ln(X : Réel) : Réel ; renvoie le logarithme népérien (Ln e = 1) d'une expression de type réel x. 7.Fonction Pi : étendue ; renvoie la valeur Pi, définie comme 3.1415926535. 8. Fonction Sin(X : Étendu) : Étendu ; renvoie le sinus de l'argument. 9.Function Sqr(X : étendu) : étendu ; renvoie le carré de l'argument. 10.Function Sqrt(X : étendu) : étendu ; renvoie la racine carrée de l'argument. Procédures et fonctions de conversion de valeur 1. Procédure Str(X [: Largeur [: Décimales]]; var S); convertit le nombre X en une représentation sous forme de chaîne. 2. Fonction Chr(X : octet) : Char ; renvoie le caractère avec le numéro d'index x dans la table ASCII. 3.Fonction haute (X); renvoie la plus grande valeur de la plage du paramètre. 4.FonctionBas(X); renvoie la plus petite valeur de la plage du paramètre. 5. FonctionOrd(X) : Entier Long ; renvoie la valeur ordinale d'une expression de type énumération. 6. Fonction Arrondi (X : Étendu) : LongInt ; arrondit une valeur réelle à un nombre entier. 7. Function Trunc(X : Étendu) : LongInt ; tronque une valeur de type réel en entier. 8. Procédure Val(S; var V; var Code : Entier); convertit un nombre d'une valeur de chaîne S en une représentation numérique V. Procédures et fonctions de valeur ordinale 1. Procédure Dec(var X [; N: LongInt]); soustrait un ou N de la variable X. 2. Procedure Inc(var X [; N: LongInt]); ajoute un ou N à la variable X. 3. Fonction Odd(X : LongInt) : booléen ; renvoie True si X est un nombre impair, False sinon. 4.FonctionPred(X); renvoie la valeur précédente du paramètre. 5 Fonction Succ(X); renvoie la valeur de paramètre suivante. 5. Opérateurs du langage Pascal Opérateur conditionnel Le format d'une instruction conditionnelle complète est défini comme suit : Si B alors S1 sinon S2 où B est une condition de branchement (prise de décision), une expression logique ou une relation ; S1, S2 - une instruction exécutable, simple ou composée. Lors de l'exécution d'une instruction conditionnelle, l'expression B est d'abord évaluée, puis son résultat est analysé : si B est vrai, alors l'instruction S1 est exécutée - la branche de then, et l'instruction S2 est ignorée ; si B est faux, alors l'instruction S2 - la branche else est exécutée et l'instruction S1 est ignorée. Sélectionner l'instruction La structure de l'opérateur est la suivante : les cas de c1 : consigne1 ; c2 : consigne2 ;
cn : instructionN ; autre instruction fin; où S est une expression de type ordinal dont la valeur est en cours de calcul ; c1, c2,..., on - constantes de type ordinal avec lesquelles les expressions S sont comparées ; instructionl,..., instructionN - opérateurs dont celui dont la constante correspond à la valeur de l'expression S est exécuté ; instruction - un opérateur qui est exécuté si la valeur de l'expression S ne correspond à aucune des constantes c1, o2, on. Instruction de boucle avec paramètre Lorsque l'instruction for commence à s'exécuter, les valeurs de début et de fin sont déterminées une fois, et ces valeurs sont conservées tout au long de l'exécution de l'instruction for. L'instruction contenue dans le corps de l'instruction for est exécutée une fois pour chaque valeur comprise entre les valeurs de début et de fin. Le compteur de boucle est toujours initialisé à une valeur initiale. Instruction de boucle avec précondition Tandis que B fait S; où B est une condition logique dont la véracité est vérifiée (c'est une condition de fin de boucle)$; S - corps de la boucle - une instruction. L'expression qui contrôle la répétition d'une instruction doit être de type booléen. Il est évalué avant l'exécution de l'instruction interne. L'instruction interne est réexécutée tant que l'expression est évaluée à Trie. Si l'expression prend la valeur False dès le début, l'instruction contenue dans l'instruction de boucle de précondition n'est pas exécutée. Instruction de boucle avec postcondition répéter S jusqu'à B ; où B est une condition logique dont la véracité est vérifiée (c'est une condition de fin de boucle) ; S - une ou plusieurs instructions de corps de boucle. Le résultat de l'expression doit être de type booléen. Les instructions comprises entre les mots clés repeat et until sont exécutées séquentiellement jusqu'à ce que le résultat de l'expression soit évalué à True. La séquence d'instructions sera exécutée au moins une fois car l'expression est évaluée après chaque exécution de la séquence d'instructions. 6. Le concept d'algorithme auxiliaire L'algorithme de résolution de problèmes est conçu en décomposant l'ensemble du problème en sous-tâches distinctes. En règle générale, les sous-tâches sont implémentées sous forme de sous-programmes. Un sous-programme est un algorithme auxiliaire qui est utilisé à plusieurs reprises dans l'algorithme principal avec différentes valeurs de certaines quantités entrantes, appelées paramètres. Un sous-programme dans les langages de programmation est une séquence d'instructions qui sont définies et écrites à un seul endroit du programme, mais elles peuvent être appelées pour être exécutées à partir d'un ou plusieurs points du programme. Chaque sous-programme est identifié par un nom unique. Il existe deux types de sous-programmes en Pascal, les procédures et les fonctions. Une procédure et une fonction sont une séquence nommée de déclarations et d'instructions. Lors de l'utilisation de procédures ou de fonctions, le programme doit contenir le texte de la procédure ou de la fonction et un appel à la procédure ou à la fonction. Les paramètres spécifiés dans la description sont dits formels, ceux spécifiés dans l'appel au sous-programme sont dits réels. Tous les paramètres formels peuvent être divisés dans les catégories suivantes : 1) paramètres-variables ; 2) paramètres constants ; 3) valeurs des paramètres ; 4) paramètres de procédure et paramètres de fonction, c'est-à-dire paramètres de type procédural ; 5) paramètres variables non typés. Les textes des procédures et des fonctions sont placés dans les descriptions des procédures et des fonctions. Passer des noms de procédure et de fonction en tant que paramètres Dans de nombreux problèmes, notamment en mathématiques computationnelles, il est nécessaire de passer les noms des procédures et des fonctions en tant que paramètres. Pour ce faire, TURBO PASCAL a introduit un nouveau type de données - procédural ou fonctionnel, selon ce qui est décrit. (Les types de procédure et de fonction sont décrits dans la section de déclaration de type.) Une fonction et un type procédural sont définis comme l'en-tête d'une procédure et d'une fonction avec une liste de paramètres formels mais sans nom. Il est possible de définir une fonction ou un type procédural sans paramètre, par exemple : type Proc = procédure ; Après avoir déclaré un type procédural ou fonctionnel, il peut être utilisé pour décrire des paramètres formels - les noms des procédures et des fonctions. De plus, il est nécessaire d'écrire ces procédures ou fonctions réelles dont les noms seront passés en paramètres réels. 7. Procédures et fonctions en Pascal Procédures en Pascal La description de la procédure se compose d'un en-tête et d'un bloc qui, à l'exception de la section de connexion du module, ne diffèrent pas du bloc de programme. L'en-tête se compose du mot-clé Procedure, du nom de la procédure et d'une liste facultative de paramètres formels entre parenthèses : Procédure <nom> [(<liste des paramètres formels>)] ; Pour chaque paramètre formel, son type doit être défini. Les groupes de paramètres dans une description de procédure sont séparés par des points-virgules. La structure de la procédure est presque complètement similaire au programme. Cependant, il n'y a pas de section de connexion de module dans le bloc de procédure. Le bloc se compose de deux parties : descriptive et exécutive. La partie descriptive contient une description des éléments de la procédure. Et dans la partie exécutive, les actions sont indiquées avec des éléments de programme accessibles à la procédure (par exemple, des variables globales et des constantes), qui permettent d'obtenir le résultat requis. La section d'instructions d'une procédure diffère de la section d'instructions d'un programme uniquement en ce que le mot-clé end termine la section par un point-virgule au lieu d'un point. Une instruction d'appel de procédure est utilisée pour appeler une procédure. Il se compose du nom de la procédure et d'une liste d'arguments entre parenthèses. Les instructions à exécuter lors de l'exécution de la procédure sont contenues dans la partie instruction du module procédure. Parfois, vous voulez qu'une procédure s'appelle elle-même. Cette façon d'appeler s'appelle la récursivité. La récursivité est utile dans les cas où la tâche principale peut être divisée en sous-tâches, chacune étant implémentée selon un algorithme qui coïncide avec la principale. Fonctions en Pascal Une déclaration de fonction définit la partie du programme dans laquelle la valeur est calculée et renvoyée. Une description de fonction se compose d'un en-tête et d'un bloc. L'en-tête contient le mot clé Function, le nom de la fonction, une liste facultative de paramètres formels entre parenthèses et le type de retour de la fonction. La vue générale de l'en-tête de la fonction est la suivante : Fonction <nom> [(<liste des paramètres formels>)] : <type de retour> ; Dans l'implémentation Borland de Turbo Pascal 7.0, la valeur de retour d'une fonction ne peut pas être de type composite. Et le langage Object Pascal utilisé dans les environnements de développement intégrés Borland Delphi permet tout type de résultat de retour, à l'exception du type de fichier. Un bloc fonction est un bloc local, dont la structure est similaire à celle d'un bloc de procédure. Le corps d'une fonction doit contenir au moins une instruction d'affectation, à gauche de laquelle se trouve le nom de la fonction. C'est elle qui détermine la valeur renvoyée par la fonction. S'il existe plusieurs instructions de ce type, le résultat de la fonction sera la valeur de la dernière instruction d'affectation exécutée. La fonction est activée lorsque la fonction est appelée. Lorsqu'une fonction est appelée, l'identifiant de la fonction et tous les paramètres nécessaires pour évaluer la fonction sont spécifiés. Un appel de fonction peut être inclus dans des expressions en tant qu'opérande. Lorsque l'expression est évaluée, la fonction est exécutée et la valeur de l'opérande devient la valeur renvoyée par la fonction. La partie opérateur du bloc fonction spécifie les instructions qui doivent être exécutées lorsque la fonction est activée. Un module doit contenir au moins une instruction d'affectation qui affecte une valeur à un identificateur de fonction. Le résultat de la fonction est la dernière valeur attribuée. S'il n'y a pas une telle instruction d'affectation, ou si elle n'a pas été exécutée, alors la valeur de retour de la fonction est indéfinie. Si un identificateur de fonction est utilisé lors de l'appel d'une fonction dans un module - une fonction, alors la fonction est exécutée de manière récursive. 8. Transmettez les descriptions et la connexion des sous-programmes. Directif Un programme peut contenir plusieurs sous-programmes, c'est-à-dire que la structure du programme peut être compliquée. Cependant, ces sous-programmes peuvent être au même niveau d'imbrication, de sorte que la déclaration du sous-programme doit venir en premier, puis son appel, à moins qu'une déclaration directe spéciale ne soit utilisée. Une déclaration de procédure qui contient une directive forward au lieu d'un bloc d'instructions est appelée une déclaration forward. Quelque part après cette déclaration, une procédure doit être définie par une déclaration de définition. Une déclaration de définition est une déclaration qui utilise le même identificateur de procédure mais omet la liste des paramètres formels et inclut un bloc d'instructions. La déclaration directe et la déclaration de définition doivent apparaître dans la même partie de la déclaration de procédure et de fonction. Entre elles, d'autres procédures et fonctions peuvent être déclarées qui peuvent faire référence à la procédure de déclaration en avant. Ainsi, la récursivité mutuelle est possible. La description avant et la description de définition constituent la description complète de la procédure. La procédure est considérée comme étant décrite à l'aide de la description directe. Si le programme contient beaucoup de sous-programmes, le programme cessera d'être visuel, il sera difficile d'y naviguer. Pour éviter cela, certaines routines sont stockées sous forme de fichiers source sur le disque et, si nécessaire, elles sont connectées au programme principal au stade de la compilation à l'aide d'une directive de compilation. Une directive est un commentaire spécial qui peut être placé n'importe où dans un programme, là où un commentaire normal peut se trouver. Cependant, ils diffèrent en ce que la directive a une notation spéciale : immédiatement après la parenthèse fermante, sans espace, le signe $ est écrit, puis, toujours sans espace, la directive est indiquée. Exemple: 1) {$E+} - émule un coprocesseur mathématique ; 2) {$F+} - forme le type lointain des procédures et fonctions d'appel ; 3) {$N+} - utilise un coprocesseur mathématique ; 4) {$R+} - vérifie si les plages sont hors limites. Certains commutateurs de compilation peuvent contenir un paramètre, par exemple : {$I file name} - inclut le fichier nommé dans le texte du programme compilé 9. Paramètres du sous-programme La description d'une procédure ou d'une fonction spécifie une liste de paramètres formels. Chaque paramètre déclaré dans une liste de paramètres formels est local à la procédure ou à la fonction décrite et peut être référencé par son identifiant dans le module associé à cette procédure ou fonction. Il existe trois types de paramètres : valeur, variable et variable non typée. Ils se caractérisent comme suit : 1. Un groupe de paramètres sans mot-clé précédent est une liste de paramètres de valeur. 2. Un groupe de paramètres précédé du mot clé const et suivi d'un type est une liste de paramètres constants. 3. Un groupe de paramètres précédé du mot-clé var et suivi d'un type est une liste de paramètres variables. Paramètres de valeur Un paramètre de valeur formel est traité comme une variable locale à la procédure ou à la fonction, sauf qu'il tire sa valeur initiale du paramètre réel correspondant lorsque la procédure ou la fonction est invoquée. Les modifications subies par un paramètre de valeur formel n'affectent pas la valeur du paramètre réel. La valeur du paramètre de valeur réelle correspondante doit être une expression et sa valeur ne doit pas être un type de fichier ou un type de structure contenant un type de fichier. Le paramètre réel doit être d'un type dont l'affectation est compatible avec le type du paramètre de valeur formelle. Si le paramètre est de type chaîne, le paramètre formel aura un attribut de taille de 255. Paramètres constants Dans le corps d'un sous-programme, la valeur d'un paramètre constant ne peut pas être modifiée. Les paramètres-constantes peuvent être utilisés pour agencer les paramètres dont les changements dans le sous-programme sont indésirables et doivent être interdits. Paramètres variables Un paramètre variable est utilisé lorsqu'une valeur doit être passée d'un sous-programme à un bloc appelant. Dans ce cas, lorsque le sous-programme est appelé, le paramètre formel est remplacé par l'argument variable et toute modification du paramètre formel est reflétée dans l'argument. Variables procédurales Après avoir défini un type procédural, il devient possible de décrire des variables de ce type. Ces variables sont appelées variables procédurales. Comme une variable entière à laquelle on peut attribuer une valeur de type entier, une variable procédurale peut se voir attribuer une valeur de type procédural. Une telle valeur pourrait, bien sûr, être une autre variable de procédure, mais il pourrait également s'agir d'un identifiant de procédure ou de fonction. Dans ce contexte, la déclaration d'une procédure ou d'une fonction peut être considérée comme la déclaration d'un type particulier de constante dont la valeur est la procédure ou la fonction. Comme pour toute autre affectation, les valeurs de la variable du côté gauche et du côté droit doivent être compatibles avec l'affectation. Les types procéduraux, pour être compatibles avec l'affectation, doivent avoir le même nombre de paramètres, et les paramètres dans les positions correspondantes doivent être du même type. Les noms de paramètre dans une déclaration de type procédural n'ont aucun effet. De plus, pour assurer la compatibilité des affectations, une procédure ou une fonction, si elle doit être affectée à une variable de procédure, ne doit pas être standard ou imbriquée. 10. Types de paramètres de sous-programme Paramètres de valeur Un paramètre de valeur formel est traité comme une variable locale ; il obtient sa valeur initiale du paramètre réel correspondant lorsque la procédure ou la fonction est invoquée. Les modifications subies par un paramètre de valeur formel n'affectent pas la valeur du paramètre réel. La valeur réelle correspondante du paramètre value doit être une expression et sa valeur ne doit pas être d'un type de fichier. Paramètres constants Les paramètres formels constants obtiennent leur valeur lorsqu'une procédure ou une fonction est invoquée. Les affectations à un paramètre constant formel ne sont pas autorisées. Un paramètre constant formel ne peut pas être passé comme paramètre réel à une autre procédure ou fonction. Paramètres variables Un paramètre variable est utilisé lorsqu'une valeur doit être transmise d'une procédure ou d'une fonction au programme appelant. Lorsqu'elle est activée, la variable-paramètre formelle est remplacée par la variable réelle, les modifications apportées à la variable-paramètre formelle sont reflétées dans le paramètre réel. Paramètres non typés Lorsque le paramètre formel est un paramètre variable non typé, le paramètre réel correspondant peut être une référence variable ou constante. Un paramètre non typé déclaré avec le mot clé var peut être modifié, tandis qu'un paramètre non typé déclaré avec le mot clé const est en lecture seule. Variables procédurales Après avoir défini un type procédural, il devient possible de décrire des variables de ce type. Ces variables sont appelées variables procédurales. Une variable procédurale peut se voir attribuer une valeur de type procédural. La procédure ou fonction en affectation doit être : 1) non standard ; 2) non imbriqué ; 3) pas une procédure de type inline ; 4) pas par la procédure d'interruption. Paramètres de type procédural Puisque les types procéduraux peuvent être utilisés dans n'importe quel contexte, il est possible de décrire des procédures ou des fonctions qui prennent des procédures et des fonctions comme paramètres. Les paramètres de type procédural sont particulièrement utiles lorsque vous devez effectuer des actions courantes sur plusieurs procédures ou fonctions. Si une procédure ou une fonction doit être passée en paramètre, elle doit suivre les mêmes règles de compatibilité de type que l'affectation. Autrement dit, ces procédures ou fonctions doivent être compilées avec la directive far, elles ne peuvent pas être des fonctions intégrées, elles ne peuvent pas être imbriquées et elles ne peuvent pas être décrites avec les attributs inline ou interrupt. 11. Type de chaîne en Pascal. Procédures et fonctions pour les variables de type chaîne Une séquence de caractères d'une certaine longueur est appelée une chaîne. Les variables de type chaîne sont définies en spécifiant le nom de la variable, la chaîne de mots réservés et éventuellement, mais pas nécessairement, en spécifiant la taille maximale, c'est-à-dire la longueur de la chaîne, entre crochets. Si vous ne définissez pas la taille de chaîne maximale, elle sera par défaut de 255, c'est-à-dire que la chaîne sera composée de 255 caractères. Chaque élément d'une chaîne peut être référencé par son numéro. Cependant, les chaînes sont entrées et sorties dans leur ensemble, et non élément par élément, comme c'est le cas avec les tableaux. Le nombre de caractères saisis ne doit pas dépasser celui spécifié dans la taille de chaîne maximale, donc si un tel excès se produit, les caractères "supplémentaires" seront ignorés. Procédures et fonctions pour les variables de type chaîne 1. Copie de fonction (S : chaîne ; index, nombre : nombre entier) : chaîne ; Renvoie une sous-chaîne d'une chaîne. S est une expression de type String. Index et Count sont des expressions de type entier. La fonction renvoie une chaîne contenant Count caractères à partir de la position Index. Si Index est supérieur à la longueur de S, la fonction renvoie une chaîne vide. 2. Procédure Delete(var S : String ; Index, Count : Integer) ; Supprime une sous-chaîne de caractères de longueur Count de la chaîne S, en commençant à la position Index. S est une variable de type String. Index et Count sont des expressions de type entier. Si Index est supérieur à la longueur de S, aucun caractère n'est supprimé. 3. Insertion de la procédure (Source : Chaîne ; var S : Chaîne ; Index : Entier) ; Concatène une sous-chaîne dans une chaîne, en commençant à une position spécifiée. Source est une expression de type String. S est une variable de type String de n'importe quelle longueur. Index est une expression de type entier. Insert insère Source dans S, en commençant à la position S. 4. Longueur de la fonction (S : chaîne) : nombre entier ; Renvoie le nombre de caractères réellement utilisés dans la chaîne S. Notez que lors de l'utilisation de chaînes terminées par un caractère nul, le nombre de caractères n'est pas nécessairement égal au nombre d'octets. 5. Fonction Pos(Substr : Chaîne ; S : Chaîne) : Entier ; Recherche une sous-chaîne dans une chaîne. Pos cherche Substr à l'intérieur de S et renvoie une valeur entière qui est l'index du premier caractère de Substr dans S. Si Substr n'est pas trouvé, Pos renvoie zéro. 12. Enregistrements Un enregistrement est une collection d'un nombre limité de composants logiquement liés appartenant à différents types. Les composants d'un enregistrement sont appelés champs, chacun étant identifié par un nom. Un champ d'enregistrement contient le nom du champ, suivi de deux-points pour indiquer le type du champ. Les champs d'enregistrement peuvent être de n'importe quel type autorisé en Pascal, à l'exception du type de fichier. La description d'un enregistrement en langage Pascal s'effectue à l'aide du mot de service ENREGISTREMENT, suivi de la description des composants de l'enregistrement. La description de l'entrée se termine par le mot de service END. Par exemple, un bloc-notes contient des noms de famille, des initiales et des numéros de téléphone, il est donc pratique de représenter une ligne distincte dans un bloc-notes sous la forme de l'entrée suivante : type Ligne = Enregistrement FIO : Chaîne[20] ; TEL : Chaîne[7] ; fin; var str : ligne ; Les descriptions d'enregistrements sont également possibles sans utiliser le nom du type, par exemple : var str : enregistrement FIO : Chaîne[20] ; TEL : Chaîne[7] ; fin; La référence à un enregistrement dans son ensemble n'est autorisée que dans les instructions d'affectation où des noms d'enregistrement du même type sont utilisés à gauche et à droite du signe d'affectation. Dans tous les autres cas, des champs d'enregistrements distincts sont exploités. Pour faire référence à un composant d'enregistrement individuel, vous devez spécifier le nom de l'enregistrement et, à l'aide d'un point, spécifier le nom du champ souhaité. Un tel nom est appelé un nom composé. Un composant d'enregistrement peut également être un enregistrement, auquel cas le nom distinctif ne contiendra pas deux, mais plusieurs noms. Le référencement des composants d'enregistrement peut être simplifié en utilisant l'opérateur with append. Il vous permet de remplacer les noms composés qui caractérisent chaque champ par des noms de champ uniquement et de définir le nom de l'enregistrement dans l'instruction de jointure. Parfois, le contenu d'un enregistrement individuel dépend de la valeur d'un de ses champs. Dans le langage Pascal, une description d'enregistrement est autorisée, composée d'une partie commune et d'une variante. La partie variante est spécifiée à l'aide du cas P de construction, où P est le nom du champ de la partie commune de l'enregistrement. Les valeurs possibles acceptées par ce champ sont répertoriées de la même manière que dans l'instruction variant. Cependant, au lieu de spécifier l'action à effectuer, comme c'est le cas dans une instruction variant, les champs variant sont spécifiés entre parenthèses. La description de la partie variante se termine par le mot de service end. Le type de champ P peut être spécifié dans l'en-tête de la partie variante. Les enregistrements sont initialisés à l'aide de constantes typées. 13. Ensembles Le concept d'ensemble dans le langage Pascal est basé sur le concept mathématique d'ensembles : c'est une collection limitée de différents éléments. Un type de données énuméré ou intervalle est utilisé pour construire un type d'ensemble concret. Le type des éléments qui composent un ensemble est appelé le type de base. Un type multiple est décrit à l'aide du Jeu de mots fonction, par exemple : type M = Ensemble de B ; où M est le type pluriel, B est le type de base. L'appartenance des variables à un type pluriel peut être déterminée directement dans la section de déclaration des variables. Les constantes de type ensemble sont écrites sous la forme d'une séquence entre crochets d'éléments ou d'intervalles de type de base, séparés par des virgules. Les opérations d'affectation (:=), d'union (+), d'intersection (*) et de soustraction (-) s'appliquent aux variables et aux constantes d'un type ensemble. Le résultat de ces opérations est une valeur de type pluriel : 1) ['A','B'] + ['A','D'] donnera ['A','B','D'] ; 2) ['A'] * ['A','B','C'] donnera ['A'] ; 3) ['A','B','C'] - ['A','B'] donnera ['C'] Les opérations suivantes sont applicables à plusieurs valeurs : identité (=), non-identité (<>), contenu dans (<=), contient (>=). Le résultat de ces opérations est de type booléen : 1) ['A','B'] = ['A','C'] donnera FALSE ; 2) ['A','B'] <> ['A','C'] donnera VRAI ; 3) ['B'] <= ['B','C'] donnera VRAI ; 4) ['C','D'] >= ['A'] donnera FALSE. En plus de ces opérations, pour travailler avec des valeurs d'un type d'ensemble, on utilise l'opération in, qui vérifie si l'élément du type de base à gauche du signe d'opération appartient à l'ensemble à droite du signe d'opération . Le résultat de cette opération est un booléen. Les valeurs de type multiple ne peuvent pas être des éléments d'une liste d'E/S. Dans chaque implémentation concrète du compilateur à partir du langage Pascal, le nombre d'éléments du type de base sur lequel l'ensemble est construit est limité. 14. Fichiers. Opérations sur les fichiers Le type de données de fichier définit une collection ordonnée de composants du même type. Lorsque vous travaillez avec des fichiers, des opérations d'E / S sont effectuées. Une opération d'entrée est un transfert de données d'un périphérique externe vers la mémoire, une opération de sortie est un transfert de données de la mémoire vers un périphérique externe. Fichiers texte Pour décrire de tels fichiers, il existe un type Texte : var TF1, TF2 : texte ; Fichiers de composants Un composant ou fichier typé est un fichier avec le type déclaré de ses composants. type M = fichier de T ; où M est le nom du type de fichier ; T - type de composant. Les opérations sont effectuées à l'aide de procédures. Écrire(f, X1,X2,...XK) Fichiers non typés Les fichiers non typés vous permettent d'écrire des sections arbitraires de la mémoire de l'ordinateur sur le disque et de les lire. var f : Fichier ; 1. Procedure Assign(var F; FileName: String); Il associe un nom de fichier à une variable. 2. Procédure Close(var F); Il rompt le lien entre la variable de fichier et le fichier du disque externe et ferme le fichier. 3.Fonction Eof(var F) : booléen ; {Fichiers typés ou non typés} Fonction Eof[(var F : Texte)] : Booléen ; {fichiers texte} Vérifie la fin d'un fichier. 4. Procédure d'effacement (var F); Supprime le fichier externe associé à F. 5. Fonction FileSize(var F) : nombre entier ; Renvoie la taille en octets du fichier F. 6.Fonction FilePos(varF) : LongInt ; Renvoie la position actuelle dans un fichier. 7. Procédure Reset(var F [: File; RecSize: Word]); Ouvre un fichier existant. 8. Procedure Rewrite(var F: File [; Recsize: Word]); Crée et ouvre un nouveau fichier. 9. Recherche de procédure (var F ; N : LongInt ); Déplace la position actuelle du fichier vers le composant spécifié. 10. Procedure Append(var F: Text); Ajout. 11.Fonction Eoln[(var F : Texte)] : Booléen ; Vérifie la fin d'une chaîne. 12. Procédure Lecture(F, V1 [, V2..., Vn]); {Fichiers typés et non typés} Procédure Lire([var F : Texte;] V1 [, V2..., Vn]); {fichiers texte} Lit un composant de fichier dans une variable. 13. Procédure Readln([var F : Texte;] V1 [, V2..., Vn]); Lit une chaîne de caractères dans le fichier, y compris le marqueur de fin de ligne, et se déplace au début de la suivante. 14. Fonction SeekEof[(var F : Texte)] : booléen ; Renvoie le signe de fin de fichier. Utilisé uniquement pour les fichiers texte ouverts. 15. Procédure Writeln([var F : Texte;] [P1, P2..., Pn]); {fichiers texte} Effectue une opération d'écriture, puis place un marqueur de fin de ligne dans le fichier. 15. Modules. Type de modules Une unité (UNIT) en Pascal est une bibliothèque de sous-programmes spécialement conçue. Un module, contrairement à un programme, ne peut pas être lancé pour exécution tout seul, il ne peut que participer à la construction de programmes et d'autres modules. Un module en Pascal est une unité de programme stockée séparément et compilée indépendamment. Tous les éléments de programme du module peuvent être divisés en deux parties : 1) éléments de programme destinés à être utilisés par d'autres programmes ou modules, ces éléments sont dits visibles à l'extérieur du module ; 2) les éléments logiciels qui ne sont nécessaires qu'au fonctionnement du module lui-même, ils sont dits invisibles (ou masqués). unité <nom du module> ; {titre du module} interface {description des éléments de programme visibles du module} la mise en oeuvre {description des éléments de programmation cachés du module} commencer {instructions d'initialisation d'élément de module} fin. Pour faire référence à une variable déclarée dans un module, vous devez utiliser un nom composé composé du nom du module et du nom de la variable, séparés par un point. L'utilisation récursive des modules est interdite. Listons les types de modules. 1. Module SYSTÈME. Le module SYSTEM implémente des routines de support de niveau inférieur pour toutes les fonctionnalités intégrées telles que les E/S, la manipulation de chaînes, les opérations en virgule flottante et l'allocation de mémoire dynamique. 2.Module DOS. Le module Dos implémente de nombreuses routines et fonctions Pascal équivalentes aux appels DOS les plus couramment utilisés, tels que GetTime, SetTime, DiskSize, etc. 3. Module CRT. Le module CRT implémente un certain nombre de programmes puissants qui offrent un contrôle total sur les fonctionnalités du PC, telles que le contrôle du mode écran, les codes de clavier étendus, les couleurs, les fenêtres et les sons. 4. Module GRAPHIQUE. À l'aide des procédures et des fonctions incluses dans ce module, vous pouvez créer divers graphiques à l'écran. 5. Module SUPERPOSITION. Le module OVERLAY vous permet de réduire les besoins en mémoire d'un programme DOS en mode réel. 16. Type de données de référence. mémoire dynamique. variables dynamiques. Travailler avec la mémoire dynamique Une variable statique (allouée statiquement) est une variable déclarée explicitement dans le programme, elle est référencée par son nom. La place en mémoire pour placer les variables statiques est déterminée lors de la compilation du programme. Contrairement à ces variables statiques, les programmes Pascal peuvent créer des variables dynamiques. La principale propriété des variables dynamiques est qu'elles sont créées et qu'une mémoire leur est allouée lors de l'exécution du programme. Les variables dynamiques sont placées dans une zone de mémoire dynamique (heap-area). Une variable dynamique n'est pas spécifiée explicitement dans les déclarations de variable et ne peut pas être référencée par son nom. Ces variables sont accessibles à l'aide de pointeurs et de références. Un type de référence (pointeur) définit un ensemble de valeurs qui pointent vers des variables dynamiques d'un type particulier, appelé le type de base. Une variable de type référence contient l'adresse d'une variable dynamique en mémoire. Si le type de base est un identificateur non déclaré, il doit être déclaré dans la même partie de la déclaration de type que le type pointeur. Le mot réservé nil désigne une constante avec une valeur de pointeur qui ne pointe vers rien. Donnons un exemple de description des variables dynamiques. var p1, p2 : ^réel ; p3, p4 : ^entier ;
Procédures et fonctions de la mémoire dynamique 1. Procédure Nouveau{var p : pointeur). Alloue de l'espace dans la zone de mémoire dynamique pour accueillir la variable dynamique p", et attribue son adresse au pointeur p. 2. Procédure Dispose(var p : pointeur). Libère la mémoire allouée à l'allocation dynamique des variables par la procédure New, et la valeur du pointeur p devient indéfinie. 3. Procédure GetMem(var p : pointeur ; taille : mot). Alloue une section de mémoire dans la zone de tas, attribue l'adresse de son début au pointeur p, la taille de la section en octets est spécifiée par le paramètre size. 4. Procédure FreeMem(varp : pointeur ; taille : mot). Libère la zone mémoire dont l'adresse de début est spécifiée par le pointeur p et la taille est spécifiée par le paramètre size. La valeur du pointeur p devient indéfinie. 5. La procédure Mark{var p : Pointer) écrit dans le pointeur p l'adresse du début de la section de mémoire dynamique libre au moment de son appel. 6. La procédure Release(var p: Pointer) libère une section de mémoire dynamique, à partir de l'adresse écrite sur le pointeur p par la procédure Mark, c'est-à-dire efface la mémoire dynamique qui était occupée après l'appel à la procédure Mark. 7. Fonction MaxAvail : Entier long renvoie la longueur en octets de la plus longue section libre de mémoire dynamique. 8. Fonction MemAvail : Entier long renvoie la quantité totale de mémoire dynamique libre en octets. 9. La fonction d'assistance SizeOf(X):Word renvoie la taille en octets occupée par X, où X peut être soit un nom de variable de n'importe quel type, soit un nom de type. 17. Structures de données abstraites Les types de données structurés, tels que les tableaux, les ensembles et les enregistrements, sont des structures statiques car leur taille ne change pas pendant toute l'exécution du programme. Il est souvent nécessaire que les structures de données changent de taille au cours de la résolution d'un problème. De telles structures de données sont dites dynamiques. Ceux-ci incluent les piles, les files d'attente, les listes, les arbres, etc. La description de structures dynamiques à l'aide de tableaux, d'enregistrements et de fichiers entraîne une utilisation inutile de la mémoire de l'ordinateur et augmente le temps de résolution des problèmes. Chaque composant de toute structure dynamique est un enregistrement contenant au moins deux champs : un champ de type "pointeur" et le second - pour le placement des données. En général, un enregistrement peut contenir non pas un, mais plusieurs pointeurs et plusieurs champs de données. Un champ de données peut être une variable, un tableau, un ensemble ou un enregistrement. Si la partie pointant contient l'adresse d'un élément de la liste, alors la liste est dite unidirectionnelle (ou simplement liée). S'il contient deux composants, il est doublement connecté. Vous pouvez effectuer diverses opérations sur les listes, par exemple : 1) ajouter un élément à la liste ; 2) supprimer un élément de la liste avec une clé donnée ; 3) rechercher un élément avec une valeur donnée du champ clé ; 4) trier les éléments de la liste ; 5) division de la liste en deux ou plusieurs listes ; 6) combiner deux ou plusieurs listes en une seule ; 7) autres opérations. Cependant, en règle générale, la nécessité de toutes les opérations pour résoudre divers problèmes ne se pose pas. Ainsi, selon les opérations de base à appliquer, il existe différents types de listes. Les plus populaires d'entre eux sont la pile et la file d'attente. 18. Piles Une pile est une structure de données dynamique, l'ajout d'un composant auquel et la suppression d'un composant à partir de laquelle sont réalisés à partir d'une extrémité, appelée le sommet de la pile. La pile fonctionne sur le principe du LIFO (Last-In, First-Out) - "Dernier entré, premier sorti". Trois opérations sont généralement effectuées sur les piles : 1) formation initiale de la pile (enregistrement du premier composant) ; 2) ajouter un composant à la pile ; 3) sélection du composant (suppression). Pour former une pile et travailler avec elle, vous devez disposer de deux variables de type "pointeur", dont la première détermine le sommet de la pile et la seconde est auxiliaire. Exemple. Écrivez un programme qui forme une pile, y ajoute un nombre arbitraire de composants, puis lit tous les composants. Programme PILE ; utilise Crt ; type Alpha = Chaîne[10] ; PComp = ^Comp; Comp = enregistrement SD : alpha ; pSuivant : PComp fin; var pTop : PComp ; sc : alpha ; Créer ProcedureStack(var pTop: PComp; var sC: Alfa); commencer Nouveau(pHaut); pHaut^.pSuivant := NUL ; pHaut^.sD:= sC ; fin; Ajouter ProcedureComp(var pTop : PComp ; var sC : Alfa ); var pAux : PComp ; commencer NOUVEAU(pAux); pAux^.pSuivant := pHaut ; pHaut :=pAux ; pHaut^.sD:= sC ; fin; Procédure DelComp(var pTop : PComp ; var sC : ALFA ); commencer sC:= pHaut^.sD ; pHaut:= pHaut^.pSuivant ; fin; commencer Clrscr ; writeln( ENTER STRING ); readln(sc); CreateStack(pTop, sc); répéter writeln( ENTER STRING ); readln(sc); AddComp(pTop, sc); jusqu'à ce que sC = 'FIN' ; 19. Files d'attente Une file d'attente est une structure de données dynamique dans laquelle un composant est ajouté à une extrémité et récupéré à l'autre extrémité. La file d'attente fonctionne sur le principe du FIFO (First-In, First-Out) - "Premier entré, premier servi". Exemple. Écrivez un programme qui forme une file d'attente, y ajoute un nombre arbitraire de composants, puis lit tous les composants. Programme FILE D'ATTENTE ; utilise Crt ; type Alpha = Chaîne[10] ; PComp = ^Comp; Comp = enregistrement SD : alpha ; pSuivant : PComp ; fin; var pBegin, pEnd : PComp ; sc : alpha ; Créer ProcedureQueue(var pBegin,pEnd : PComp ; var sc : Alfa); commencer Nouveau(pBegin); pBegin^.pNext:= NIL ; pBegin^.sD:= sC; pFin := pDébut ; fin; Procédure AddQueue(var pEnd : PComp ; var sC : alpha); var pAux : PComp ; commencer Nouveau(pAux); pAux^.pNext:= NIL ; pFin^.pSuivant := pAux ; pFin := pAux ; pEnd^.sD:= sC; fin; Procédure DelQueue(var pBegin : PComp ; var sC : alpha); commencer sC:=pBegin^.sD ; pDébut := pDébut^.pSuivant ; fin; commencer Clrscr ; writeln( ENTER STRING ); readln(sc); CreateQueue(pBegin, pEnd, sc); répéter writeln( ENTER STRING ); readln(sc); AddQueue(pEnd, sc); jusqu'à ce que sC = 'FIN' ; 20. Structures de données arborescentes Une structure de données arborescente est un ensemble fini d'éléments-nœuds entre lesquels il existe des relations - la connexion entre la source et le généré. Si l'on utilise la définition récursive proposée par N. Wirth, alors une structure de données arborescente de type de base t est soit une structure vide, soit un nœud de type t, avec lequel un ensemble fini de structures arborescentes de type de base t, appelées sous-arbres, est associée. Ensuite, nous donnons les définitions utilisées lorsque l'on travaille avec des structures arborescentes. Si le nœud y est situé directement en dessous du nœud x, alors le nœud y est appelé le descendant immédiat du nœud x, et x est l'ancêtre immédiat du nœud y, c'est-à-dire que si le nœud x est au i-ème niveau, alors le nœud y est en conséquence situé au (i + 1 ) - ème niveau. Le niveau maximum d'un nœud d'arbre est appelé la hauteur ou la profondeur de l'arbre. Un ancêtre n'a pas qu'un seul nœud de l'arbre - sa racine. Les nœuds d'arbre qui n'ont pas d'enfants sont appelés nœuds feuilles (ou feuilles de l'arbre). Tous les autres nœuds sont appelés nœuds internes. Le nombre d'enfants immédiats d'un nœud détermine le degré de ce nœud, et le degré maximum possible d'un nœud dans un arbre donné détermine le degré de l'arbre. Les ancêtres et les descendants ne peuvent pas être échangés, c'est-à-dire que la connexion entre l'original et le généré n'agit que dans un sens. Si vous allez de la racine de l'arbre à un nœud particulier, alors le nombre de branches de l'arbre qui seront parcourues dans ce cas s'appelle la longueur du chemin pour ce nœud. Si toutes les branches (nœuds) d'un arbre sont ordonnées, alors l'arbre est dit ordonné. Les arbres binaires sont un cas particulier des structures arborescentes. Ce sont des arbres dans lesquels chaque enfant a au plus deux enfants, appelés les sous-arbres gauche et droit. Ainsi, un arbre binaire est une structure arborescente dont le degré est deux. L'ordre d'un arbre binaire est déterminé par la règle suivante : chaque nœud a son propre champ clé et, pour chaque nœud, la valeur de la clé est supérieure à toutes les clés de son sous-arbre gauche et inférieure à toutes les clés de son sous-arbre droit. Un arbre dont le degré est supérieur à deux est dit fortement ramifié. 21. Opérations sur les arbres De plus, nous considérerons toutes les opérations en relation avec les arbres binaires. I. Construire un arbre. Nous présentons un algorithme pour construire un arbre ordonné. 1. Si l'arborescence est vide, les données sont transférées à la racine de l'arborescence. Si l'arbre n'est pas vide, alors l'une de ses branches est descendue de telle manière que l'ordre de l'arbre n'est pas violé. En conséquence, le nouveau nœud devient la feuille suivante de l'arbre. 2. Pour ajouter un nœud à un arbre déjà existant, vous pouvez utiliser l'algorithme ci-dessus. 3. Lorsque vous supprimez un nœud de l'arborescence, vous devez être prudent. Si le nœud à supprimer est une feuille ou n'a qu'un seul enfant, l'opération est simple. Si le nœud à supprimer a deux descendants, alors il faudra trouver un nœud parmi ses descendants qui pourra être mis à sa place. Ceci est nécessaire en raison de l'exigence que l'arbre soit commandé. Vous pouvez le faire : échangez le nœud à supprimer avec le nœud avec la plus grande valeur de clé dans le sous-arbre de gauche, ou avec le nœud avec la plus petite valeur de clé dans le sous-arbre de droite, puis supprimez le nœud souhaité en tant que feuille. II. Recherche un nœud avec une valeur de champ clé donnée. Lors de cette opération, il est nécessaire de parcourir l'arbre. Il faut tenir compte des différentes formes d'écriture d'un arbre : préfixe, infixe et suffixe. La question se pose : comment représenter les nœuds de l'arbre pour qu'il soit plus pratique de travailler avec eux ? Il est possible de représenter un arbre à l'aide d'un tableau, où chaque nœud est décrit par une valeur de type combiné, qui a un champ d'information de type caractère et deux champs de type référence. Mais ce n'est pas très pratique, car les arbres ont un grand nombre de nœuds qui ne sont pas prédéterminés. Par conséquent, il est préférable d'utiliser des variables dynamiques lors de la description d'un arbre. Ensuite chaque nœud est représenté par une valeur de même type, qui contient une description d'un nombre donné de champs d'information, et le nombre de champs correspondants doit être égal au degré de l'arbre. Il est logique de définir l'absence de descendance par la référence nil. Alors, en Pascal, la description d'un arbre binaire pourrait ressembler à ceci : TYPE TreeLink = ^Tree ; arbre = enregistrement ; Inf : <type de données> ; Gauche, Droite : TreeLink ; Fin. 22. Exemples de mise en œuvre d'opérations 1. Construisez un arbre de XNUMX nœuds de hauteur minimale, ou un arbre parfaitement équilibré (le nombre de nœuds des sous-arbres gauche et droit d'un tel arbre ne doit pas différer de plus d'un). Algorithme de construction récursif : 1) le premier nœud est pris comme racine de l'arbre ; 2) le sous-arbre gauche de nl nœuds est construit de la même manière ; 3) le sous-arbre droit de nr nœuds est construit de la même manière ; nr = n - nl - 1 Comme champ d'information, nous prendrons les numéros de nœud saisis au clavier. La fonction récursive qui implémente cette construction ressemblera à ceci : Arbre de fonction (n : octet) : TreeLink ; Vart : TreeLink ; nl,nr,x : octet ; Commencer Si n = 0 alors Arbre := nul autre Commencer nl:= n div 2 ; nr = n - nl - 1 ; writeln('Entrez le numéro du sommet ); lireln(x); triton); t^.inf:= x; t^.left := Arbre(nl) ; t^.right:= Arbre(n°); Arbre :=t ; Fin; {Arbre} Fin. 2. Dans l'arbre binaire ordonné, recherchez le nœud avec la valeur donnée du champ clé. S'il n'y a pas un tel élément dans l'arborescence, ajoutez-le à l'arborescence. Procédure de recherche (x : octet ; var t : lien d'arbre ); Commencer Si t = nul alors Commencer Triton); t^inf := x; t^.gauche := néant ; t^.right := néant ; Fin Sinon si x < t^.inf alors Recherche(x, t^.gauche) Sinon si x > t^.inf alors Recherche(x, t^.droite) autre Commencer {traiter l'élément trouvé}
Fin; Fin. 23. Le concept de graphique. Façons de représenter un graphique Un graphe est un couple G = (V,E), où V est un ensemble d'objets de nature arbitraire, appelés sommets, et E est une famille de couples ei = (vil, vi2), vijOV, appelés arêtes. Dans le cas général, l'ensemble V et (ou) la famille E peuvent contenir un nombre infini d'éléments, mais nous ne considérerons que des graphes finis, c'est-à-dire des graphes pour lesquels V et E sont finis. Si l'ordre des éléments inclus dans ei est important, alors le graphe est appelé dirigé, abrégé - digraphe, sinon - non dirigé. Les arêtes d'un digraphe sont appelées arcs. Si e = , alors les sommets v et u sont appelés les extrémités de l'arête. On dit ici que l'arête e est adjacente (incidente) à chacun des sommets v et u. Les sommets v et et sont aussi appelés adjacents (incidents). Dans le cas général, les arêtes de la forme e = ; ces arêtes sont appelées boucles. Le degré d'un sommet de graphe est le nombre d'arêtes incidentes au sommet donné, les boucles étant comptées deux fois. Le poids d'un sommet est un nombre (réel, entier ou rationnel) attribué à un sommet donné (interprété comme un coût, un débit, etc.). Un chemin dans un graphe (ou un itinéraire dans un digraphe) est une séquence alternée de sommets et d'arêtes (ou d'arcs dans un digraphe) de la forme v0, (v0,v1), v1,..., (vn -1, vn), vn. Le nombre n est appelé la longueur du chemin. Un chemin sans arêtes répétitives est appelé une chaîne ; un chemin sans sommets répétitifs est appelé une chaîne simple. Un chemin fermé sans arêtes répétitives est appelé un cycle (ou contour dans un digraphe); sans répéter les sommets (sauf le premier et le dernier) - un cycle simple. Un graphe est dit connexe s'il existe un chemin entre deux de ses sommets, et déconnecté sinon. Il existe différentes manières de représenter des graphiques. 1. Matrice d'incidence. Il s'agit d'une matrice rectangulaire n x m, où n est le nombre de sommets et m est le nombre d'arêtes. 2. Matrice d'adjacence. Il s'agit d'une matrice carrée de dimensions n × n, où n est le nombre de sommets. 3. Liste des contiguïtés (incidents). Représente une structure de données qui pour chaque sommet du graphe stocke une liste de sommets qui lui sont adjacents. La liste est un tableau de pointeurs, dont le ième élément contient un pointeur vers la liste des sommets adjacents au ième sommet. 4. Liste des listes. Il s'agit d'une structure de données arborescente dans laquelle une branche contient des listes de sommets adjacents à chacun. 24. Diverses représentations graphiques Pour implémenter un graphique sous forme de liste d'incidences, vous pouvez utiliser le type suivant : TypeListe = ^S ; S=enregistrement ; inf : octet ; suivant : Liste ; fin; Le graphe est alors défini comme suit : Vargr : tableau[1..n] de la liste ; Passons maintenant à la procédure de parcours de graphe. Il s'agit d'un algorithme auxiliaire qui permet de visualiser tous les sommets du graphe, d'analyser tous les champs d'information. Si l'on considère un parcours de graphe en profondeur, alors il existe deux types d'algorithmes : récursifs et non récursifs. En Pascal, le parcours en profondeur ressemblerait à ceci : Procédure Obhod(gr : Graph ; k : Byte); Varg : graphe ; l:Liste ; Commencer nov[k] := faux ; g:=gr ; Tandis que g^.inf <> k faire g:= g^.suivant ; l:= g^.smeg ; Tant que l <> néant commence Si nov[l^.inf] alors Obhod(gr, l^.inf); l:= l^.suivant ; Fin; Fin; Représenter un graphe sous forme de liste de listes Un graphe peut être défini à l'aide d'une liste de listes comme suit : TypeListe = ^Tliste ; tlist=enregistrement inf : octet ; suivant : Liste ; fin; Graph = ^TGpaph ; TGpaph = enregistrement inf : octet ; smeg : Liste ; suivant : graphique ; fin; Lorsque nous parcourons le graphe en largeur, nous sélectionnons un sommet arbitraire et regardons à travers tous les sommets adjacents à la fois. Voici une procédure pour parcourir un graphe en largeur en pseudocode : Procédure Obhod2(v); Commencer file d'attente = O ; file d'attente <= v ; nov[v] = Faux ; Pendant la file d'attente <> O faire Commencer p <= file d'attente ; Pour toi en spisok(p) do Si nouveau[u] alors Commencer nov[u]:= False ; file d'attente <= u ; Fin; Fin; Fin; 25. Type d'objet en Pascal. Le concept d'objet, sa description et son utilisation Un langage de programmation orienté objet se caractérise par trois propriétés principales : 1) encapsulation. La combinaison d'enregistrements avec des procédures et des fonctions qui manipulent les champs de ces enregistrements forme un nouveau type de données - un objet ; 2) héritage. Définition d'un objet et son utilisation ultérieure pour construire une hiérarchie d'objets enfants avec la possibilité pour chaque objet enfant lié à la hiérarchie d'accéder au code et aux données de tous les objets parents ; 3) polymorphisme. Donner à une action un nom unique, qui est ensuite partagé de haut en bas dans la hiérarchie des objets, chaque objet de la hiérarchie exécutant cette action d'une manière qui lui convient. En parlant d'objet, nous introduisons un nouveau type de données - celui de l'objet. Un type d'objet est une structure composée d'un nombre fixe de composants. Chaque composant est soit un champ contenant des données d'un type strictement défini, soit une méthode qui effectue des opérations sur un objet. Un type d'objet peut hériter des composants d'un autre type d'objet. Si le type T2 hérite du type T1, alors le type T2 est un enfant du type G et le type G lui-même est un parent du type G2. Le code source suivant fournit un exemple de déclaration de type d'objet. type point = objet X, Y : entier ; fin; Rect = objet A, B : TPoint ; procédure Init(XA, YA, XB, YB : Entier); procédure Copier(var R: TRectangle); procédure Move(DX, DY : Entier); procédure Grow(DX, DY : Integer) ; procedure Intersection(var R: TRectangle); procédure Union(var R: TRectangle); fonction Contient(P : Point) : booléen ; fin; Contrairement aux autres types, les types d'objet ne peuvent être déclarés que dans la section de déclaration de type au niveau le plus externe de la portée d'un programme ou d'un module. Ainsi, les types d'objet ne peuvent pas être déclarés dans une section de déclaration de variable ou à l'intérieur d'un bloc de procédure, de fonction ou de méthode. Un type de composant de type fichier ne peut pas avoir un type d'objet ou un type de structure contenant des composants de type objet. 26. Héritage L'héritage est le processus de génération de nouveaux types enfants à partir de types parents existants, tandis que l'enfant reçoit (hérite) du parent tous ses champs et méthodes. Le type descendant, dans ce cas, est appelé le type héritier ou enfant. Et le type dont le type enfant hérite est appelé le type parent. Les champs et méthodes hérités peuvent être utilisés tels quels ou redéfinis (modifiés). N. Wirth dans son langage Pascal s'est efforcé d'obtenir un maximum de simplicité, il ne l'a donc pas compliqué en introduisant la relation d'héritage. Par conséquent, les types en Pascal ne peuvent pas hériter. Cependant, Turbo Pascal 7.0 étend ce langage pour prendre en charge l'héritage. L'une de ces extensions est une nouvelle catégorie de structure de données liée aux enregistrements, mais beaucoup plus puissante. Les types de données de cette nouvelle catégorie sont définis à l'aide du nouveau mot réservé Object. La syntaxe est très similaire à la syntaxe de définition des enregistrements : Type <nom du type> = Objet [(<nom du type parent>)] ([<portée>] <description des champs et des méthodes>)+ fin; Le signe "+" après une construction syntaxique entre parenthèses signifie que cette construction doit apparaître une ou plusieurs fois dans cette description. La portée est l'un des mots clés suivants : ▪ Privé; ▪ Protégé ; ▪ Publique. La portée caractérise à quelles parties du programme les composants dont les descriptions suivent le mot-clé qui nomme cette portée seront disponibles. Pour plus d'informations sur les portées des composants, voir la question n° 28. L'héritage est un outil puissant utilisé dans le développement de programmes. Il vous permet de mettre en œuvre dans la pratique la décomposition orientée objet du problème, en utilisant le langage pour exprimer la relation entre les objets de types qui forment une hiérarchie, et favorise également la réutilisation du code de programme. 27. Instancier des objets Une instance d'un objet est créée en déclarant une variable ou une constante d'un type d'objet, ou en appliquant la procédure New standard à une variable de type "pointeur sur un type d'objet". L'objet résultant est appelé une instance du type d'objet. Si un type d'objet contient des méthodes virtuelles, les instances de ce type d'objet doivent être initialisées en appelant un constructeur avant d'appeler une méthode virtuelle. L'affectation d'une instance d'un type d'objet n'implique pas l'initialisation de l'instance. Un objet est initialisé par le code généré par le compilateur qui s'exécute entre l'appel du constructeur et le point auquel l'exécution atteint réellement la première instruction dans le bloc de code du constructeur. Si l'instance d'objet n'est pas initialisée et que la vérification de plage est activée (par la directive {$R+}), le premier appel à la méthode virtuelle de l'instance d'objet donne une erreur d'exécution. Si la vérification de plage est désactivée par la directive {$R-}), le premier appel à une méthode virtuelle d'un objet non initialisé peut entraîner un comportement imprévisible. La règle d'initialisation obligatoire s'applique également aux instances qui sont des composants de types struct. Par exemple: var Commentaire : tableau [1..5] de TStrField ; je : entier commencer pour I := 1 à 5 do Commentaire [I].Init (1, I + 10, 40, 'first_name'); . . . pour I:= 1 à 5 faire Commentaire [I].Done; fin; Pour les instances dynamiques, l'initialisation concerne généralement le placement et le nettoyage concerne la suppression, qui est réalisée via la syntaxe étendue des procédures standard New et Dispose. Par exemple: var SP : StrFieldPtr ; commencer Nouveau(SP, Init(1, 1, 25, 'prenom'); SP^.Put('Vladimir'); SP^.Affichage ; . . . Éliminer (SP, Terminé) ; fin. Un pointeur vers un type d'objet est une affectation compatible avec un pointeur vers n'importe quel type d'objet parent, de sorte qu'au moment de l'exécution, un pointeur vers un type d'objet peut pointer vers une instance de ce type ou vers une instance de n'importe quel type enfant. 28. Composantes et portée La portée d'un identifiant de bean s'étend au-delà du type d'objet. De plus, la portée d'un identificateur de bean s'étend aux blocs de procédures, fonctions, constructeurs et destructeurs qui implémentent les méthodes du type d'objet et de ses descendants. Sur la base de ces considérations, l'identificateur de composant doit être unique dans le type d'objet et dans tous ses descendants, ainsi que dans toutes ses méthodes. Dans une déclaration de type d'objet, un en-tête de méthode peut spécifier les paramètres du type d'objet décrit, même si la déclaration n'est pas encore terminée. Considérez le schéma suivant pour une déclaration de type qui contient des composants de toutes les étendues valides : Type <nom du type> = Objet [(<nom du type parent>)] Chef <descriptions privées des champs et des méthodes> Protégé <descriptions protégées des champs et des méthodes> public <descriptions publiques des champs et des méthodes> fin; Les champs et méthodes décrits dans la section Privé ne peuvent être utilisés que dans le module contenant leurs déclarations et nulle part ailleurs. Les champs et méthodes protégés, c'est-à-dire ceux décrits dans la section Protected, sont visibles pour le module où le type est défini et pour les descendants de ce type. Les champs et les méthodes de la section Public n'ont aucune restriction quant à leur utilisation et peuvent être utilisés n'importe où dans le programme ayant accès à un objet de ce type. La portée de l'identificateur de composant décrit dans la partie privée de la déclaration de type est limitée au module (programme) qui contient la déclaration de type d'objet. En d'autres termes, les beans identificateurs privés agissent comme des identificateurs publics ordinaires dans le module qui contient la déclaration de type d'objet, et en dehors du module, tous les beans et identificateurs privés sont inconnus et inaccessibles. En plaçant des types d'objets associés dans le même module, vous pouvez faire en sorte que ces objets accèdent aux composants privés les uns des autres, et ces composants privés seront inconnus des autres modules. 29. Méthodes Une déclaration de méthode à l'intérieur d'un type d'objet correspond à une déclaration de méthode directe (forward). Ainsi, quelque part après une déclaration de type d'objet, mais dans la même portée que la portée de la déclaration de type d'objet, une méthode doit être implémentée en définissant sa déclaration. Pour les méthodes procédurales et fonctionnelles, la déclaration de définition prend la forme d'une déclaration de procédure ou de fonction ordinaire, sauf que dans ce cas, l'identificateur de procédure ou de fonction est traité comme un identificateur de méthode. La description de définition d'une méthode contient toujours un paramètre implicite avec l'identifiant Self, correspondant à un paramètre variable formel qui a un type d'objet. Dans un bloc de méthode, Self représente l'instance dont le composant de méthode a été spécifié pour invoquer la méthode. Ainsi, toute modification des valeurs des champs Self est répercutée dans l'instance. Méthodes virtuelles Les méthodes sont statiques par défaut, mais à l'exception des constructeurs, elles peuvent être virtuelles (en incluant la directive virtual dans la déclaration de la méthode). Le compilateur résout les références aux appels de méthode statique pendant le processus de compilation, tandis que les appels de méthode virtuelle sont résolus au moment de l'exécution. Ceci est parfois appelé reliure tardive. La redéfinition d'une méthode statique est indépendante de la modification de l'en-tête de la méthode. En revanche, un remplacement de méthode virtuelle doit préserver l'ordre, les types et noms de paramètres et les types de résultats de fonction, le cas échéant. De plus, la redéfinition doit à nouveau inclure la directive virtuelle. Méthodes dynamiques Borland Pascal prend en charge des méthodes à liaison tardive supplémentaires appelées méthodes dynamiques. Les méthodes dynamiques ne diffèrent des méthodes virtuelles que par la manière dont elles sont distribuées au moment de l'exécution. À tous autres égards, les méthodes dynamiques sont considérées comme équivalentes aux méthodes virtuelles. Une déclaration de méthode dynamique est équivalente à une déclaration de méthode virtuelle, mais la déclaration de méthode dynamique doit inclure l'index de méthode dynamique, qui est spécifié immédiatement après le mot-clé virtual. L'index d'une méthode dynamique doit être une constante entière comprise entre 1 et 656535 et doit être unique parmi les index des autres méthodes dynamiques contenues dans le type d'objet ou ses ancêtres. Par exemple: procedure FileOpen(var Msg: TMessage); virtuel 100 ; Un remplacement d'une méthode dynamique doit correspondre à l'ordre, aux types et aux noms des paramètres, et correspondre exactement au type de résultat de la fonction de la méthode parent. Le remplacement doit également inclure une directive virtuelle suivie du même index de méthode dynamique que celui spécifié dans le type d'objet ancêtre. 30. Constructeurs et destructeurs Les constructeurs et les destructeurs sont des formes spécialisées de méthodes. Utilisés en relation avec la syntaxe étendue des procédures standard New et Dispose, les constructeurs et les destructeurs ont la capacité de placer et de supprimer des objets dynamiques. De plus, les constructeurs ont la possibilité d'effectuer l'initialisation requise des objets contenant des méthodes virtuelles. Comme toutes les autres méthodes, les constructeurs et les destructeurs peuvent être hérités et les objets peuvent contenir n'importe quel nombre de constructeurs et de destructeurs. Les constructeurs sont utilisés pour initialiser les objets nouvellement créés. En règle générale, l'initialisation est basée sur les valeurs transmises au constructeur en tant que paramètres. Un constructeur ne peut pas être virtuel car le mécanisme de répartition d'une méthode virtuelle dépend du constructeur qui a initialisé l'objet en premier. Voici quelques exemples de constructeurs : constructeur Field.Copy(var F: Field); commencer Soi :=F ; fin; L'action principale d'un constructeur d'un type dérivé (enfant) est presque toujours d'appeler le constructeur approprié de son parent immédiat pour initialiser les champs hérités de l'objet. Après avoir exécuté cette procédure, le constructeur initialise les champs de l'objet qui n'appartiennent qu'au type dérivé. Les destructeurs sont à l'opposé des constructeurs et sont utilisés pour nettoyer les objets après leur utilisation. Normalement, le nettoyage consiste à supprimer tous les champs de pointeur dans l'objet. Noter Un destructeur peut être virtuel, et l'est souvent. Un destructeur a rarement des paramètres. Voici quelques exemples de destructeurs : destructeur Champ Terminé ; commencer FreeMem(Nom, Longueur(Nom^) + 1); fin; destructeur StrField.Done ; commencer FreeMem(Valeur, Len); Champ Terminé ; fin; Le destructeur d'un type enfant, tel que le TStrField ci-dessus. Done, supprime généralement d'abord les champs de pointeur introduits dans le type dérivé, puis, dans une dernière étape, appelle le collecteur-destructeur approprié du parent immédiat pour supprimer les champs de pointeur hérités de l'objet. 31. Destructeurs Borland Pascal fournit un type spécial de méthode appelé ramasse-miettes (ou destructeur) pour nettoyer et supprimer un objet alloué dynamiquement. Le destructeur combine l'étape de suppression d'un objet avec toute autre action ou tâche requise pour ce type d'objet. Vous pouvez définir plusieurs destructeurs pour un même type d'objet. Les destructeurs peuvent être hérités et peuvent être statiques ou virtuels. Étant donné que différents finaliseurs ont tendance à nécessiter différents types d'objets, il est généralement recommandé que les destructeurs soient toujours virtuels afin que le destructeur correct soit exécuté pour chaque type d'objet. Le destructeur de mot réservé n'a pas besoin d'être spécifié pour chaque méthode de nettoyage, même si la définition de type de l'objet contient des méthodes virtuelles. Les destructeurs ne fonctionnent vraiment que sur des objets alloués dynamiquement. Lorsqu'un objet alloué dynamiquement est nettoyé, le destructeur remplit une fonction spéciale : il s'assure que le nombre correct d'octets est toujours libéré dans la zone mémoire allouée dynamiquement. L'utilisation d'un destructeur avec des objets alloués statiquement ne peut poser aucun problème ; en fait, en ne passant pas le type de l'objet au destructeur, le programmeur prive un objet de ce type de tous les avantages de la gestion dynamique de la mémoire en Borland Pascal. Les destructeurs deviennent en fait eux-mêmes lorsque des objets polymorphes doivent être effacés et lorsque la mémoire qu'ils occupent doit être désallouée. Les objets polymorphes sont les objets qui ont été affectés à un type parent en raison des règles de compatibilité de type étendues de Borland Pascal. Le terme "polymorphe" est approprié car le code qui traite un objet "ne sait pas" exactement au moment de la compilation quel type d'objet il devra éventuellement traiter. La seule chose qu'il sait est que cet objet appartient à une hiérarchie d'objets qui sont des descendants du type d'objet spécifié. La méthode destructor elle-même peut être vide et exécuter uniquement cette fonction : destructorAnObject.Done ; commencer fin; Ce qui est utile dans ce destructeur n'est pas la propriété de son corps, cependant, le compilateur génère un code d'épilogue en réponse au mot réservé du destructeur. C'est comme un module qui n'exporte rien, mais fait un travail invisible en exécutant sa section d'initialisation avant de démarrer le programme. Toutes les actions se déroulent dans les coulisses. 32. Méthodes virtuelles Une méthode devient virtuelle si sa déclaration de type d'objet est suivie du nouveau mot réservé virtual. Si une méthode dans un type parent est déclarée comme virtuelle, toutes les méthodes portant le même nom dans les types enfants doivent également être déclarées virtuelles pour éviter une erreur du compilateur. Voici les objets de l'exemple de paie, correctement virtualisés : taper PEmployé = ^TEmployé ; Employé = objet Nom, titre : chaîne[25] ; Taux : Réel ; constructeur Init(AName, ATitle : String ; ARate : Real); fonction GetPayAmount : Réel ; virtuel; fonction GetName : chaîne ; fonction GetTitle : chaîne ; fonction GetRate : Réel ; procédure Afficher ; virtuel; fin; Toutes les heures = ^T toutes les heures ; THeure = objet(TEMPloyee); Heure : Entier ; constructeur Init(AName, ATitle : chaîne ; ARate : réel ; Heure : Entier ); fonction GetPayAmount : Réel ; virtuel; fonction GetTime : nombre entier ; fin; PSalarié = ^TSalarié ; TSalarié = objet(TEMPloyee); fonction GetPayAmount : Réel ; virtuel; fin; PCommission = ^TCommissioned ; TCommissioned = objet (salarié); Commission : Réel ; Montant des ventes : Réel ; constructeur Init(AName, ATitle : String ; ARate, ACommission, ASalesAmount: Real); fonction GetPayAmount : Réel ; virtuel; fin; Un constructeur est un type spécial de procédure qui effectue un certain travail de configuration pour le mécanisme de méthode virtuelle. De plus, le constructeur doit être appelé avant toute méthode virtuelle. Appeler une méthode virtuelle sans appeler au préalable le constructeur peut bloquer le système et le compilateur n'a aucun moyen de vérifier l'ordre dans lequel les méthodes sont appelées. Chaque type d'objet qui a des méthodes virtuelles doit avoir un constructeur. Le constructeur doit être appelé avant toute autre méthode virtuelle. L'appel d'une méthode virtuelle sans appel préalable au constructeur peut provoquer un verrouillage du système et le compilateur ne peut pas vérifier l'ordre dans lequel les méthodes sont appelées. 33. Champs de données d'objet et paramètres formels de méthode L'implication du fait que les méthodes et leurs objets partagent une portée commune est que les paramètres formels d'une méthode ne peuvent être identiques à aucun des champs de données de l'objet. Ce n'est pas une nouvelle limitation imposée par la programmation orientée objet, mais plutôt les mêmes anciennes règles de portée que Pascal a toujours eues. Cela revient à interdire que les paramètres formels d'une procédure soient identiques aux variables internes de la procédure. Prenons un exemple illustrant cette erreur pour une procédure : procédure CrunchIt(Crunchee : MyDataRec, Crunchby, Code d'erreur : entier ); var A, B : caractère ; Code Erreur : entier ; commencer . . . fin; Une erreur se produit sur la ligne contenant la déclaration de la variable locale ErrorCode. En effet, les identifiants du paramètre formel et de la variable locale sont les mêmes. Les variables locales d'une procédure et ses paramètres formels partagent une portée commune et ne peuvent donc pas être identiques. Vous recevrez un message "Erreur 4 : Identifiant en double" si vous essayez de compiler quelque chose comme ça. La même erreur se produit lors de la tentative d'assignation d'un paramètre de méthode formelle au nom du champ de l'objet auquel appartient cette méthode. Les circonstances sont quelque peu différentes, car placer un en-tête de sous-programme dans une structure de données est un clin d'œil à une innovation de Turbo Pascal, mais les principes de base de la portée de Pascal n'ont pas changé. Vous devez toujours respecter une culture particulière lors du choix des identifiants de variables et de paramètres. Certains styles de programmation permettent de nommer les champs de type afin de réduire le risque d'identificateurs en double. Par exemple, la notation hongroise suggère que les noms de champs commencent par un préfixe "m". 34. Encapsulation La combinaison de code et de données dans un objet est appelée encapsulation. En principe, il est possible de fournir suffisamment de méthodes pour que l'utilisateur d'un objet n'accède jamais directement aux champs de l'objet. Certains autres langages orientés objet, tels que Smalltalk, nécessitent une encapsulation obligatoire, mais Borland Pascal a le choix. Par exemple, les objets TEmployee et THourly sont écrits de telle manière qu'il n'est absolument pas nécessaire d'accéder directement à leurs champs de données internes : type Employé = objet Nom, titre : chaîne[25] ; Taux : Réel ; procedure Init(AName, ATitle : string; ARate : Real); fonction GetName : chaîne ; fonction GetTitle : chaîne ; fonction GetRate : Réel ; fonction GetPayAmount : Réel ; fin; THeure = objet(TEmployé) Heure : Entier ; procédure Init(AName, ATitle : chaîne ; ARate : Réel, Atime : Entier); fonction GetPayAmount : Réel ; fin; Il n'y a que quatre champs de données ici : Nom, Titre, Taux et Heure. Les méthodes GetName et GetTitle affichent respectivement le nom et le poste du collaborateur. La méthode GetPayAmount utilise Rate, et dans le cas d'un travail THourly et Time pour calculer le montant des paiements au travail. Il n'est plus nécessaire de se référer directement à ces champs de données. En supposant l'existence d'une instance AnHourly de type THourly, nous pourrions utiliser un ensemble de méthodes pour manipuler les champs de données d'AnHourly, comme ceci : avec Un faire toutes les heures commencer Init (Aleksandr Petrov, opérateur de chariot élévateur' 12.95, 62); {Affiche le nom, la fonction et le montant Paiements} Montrer; fin; Il est à noter que l'accès aux champs d'un objet ne s'effectue qu'à l'aide des méthodes de cet objet. 35. Développer des objets Si un type dérivé est défini, les méthodes du type parent sont héritées, mais elles peuvent être remplacées si vous le souhaitez. Pour remplacer une méthode héritée, déclarez simplement une nouvelle méthode avec le même nom que la méthode héritée, mais avec un corps différent et (si nécessaire) un ensemble de paramètres différent. Définissons un type enfant de TEmployee qui représente un employé rémunéré à l'heure dans l'exemple suivant : const PayPeriods = 26 ; { délais de paiement } Seuil d'heures supplémentaires = 80 ; { pour la période de paiement } FacteurHeuressupplémentaires = 1.5 ; { taux horaire } type THeure = objet(TEmployé) Heure : Entier ; procédure Init(AName, ATitle : chaîne ; ARate : Réel, Atime : Entier); fonction GetPayAmount : Réel ; fin; procédure THeure.Init(AName, ATitle: string; ARate : Réel, Atime : Entier); commencer TEMPloyee.Init(AName, ATitle, ARate); Heure := AHeure ; fin; fonction THourly.GetPayAmount : Réel ; var Heures supplémentaires : nombre entier ; commencer Heures Supplémentaires := Heure - Seuil Heures Supplémentaires ; si Heures supplémentaires > 0 alors GetPayAmount := RoundPay (OvertimeThreshold * Taux + RateOverTime * OvertimeFactor *Évaluer) d'autre GetPayAmount := RoundPay (Durée * Taux) fin; Lors de l'appel d'une méthode redéfinie, vous devez vous assurer que le type d'objet dérivé inclut la fonctionnalité du parent. De plus, toute modification de la méthode parent affecte automatiquement toutes les méthodes enfant. Remarque importante : bien que les méthodes puissent être remplacées, les champs de données ne peuvent pas l'être. Une fois qu'un champ de données a été défini dans une hiérarchie d'objets, aucun type enfant ne peut définir un champ de données portant exactement le même nom. 36. Compatibilité des types d'objets L'héritage modifie dans une certaine mesure les règles de compatibilité de type de Borland Pascal. Un descendant hérite de la compatibilité de type de tous ses ancêtres. Cette compatibilité de type étendue prend trois formes : 1) entre les implémentations d'objets ; 2) entre des pointeurs vers des implémentations d'objets ; 3) entre les paramètres formels et réels. La compatibilité des types ne s'étend que de l'enfant au parent. Par exemple, TSalaried est un enfant de TEmployee et TCommissioned est un enfant de TSalaried. Considérez les descriptions suivantes : var UnEmployé : TEmployé ; ASalarié : Tsalarié ; PCommissioned : TCommissioned ; TEmployeePtr : ^TEmployee ; TSalariéPtr : ^TSalarié ; TCommissionedPtr : ^TCommissioned ; Sous ces descriptions, les opérateurs d'affectation suivants sont valides : UnEmployé :=UnSalarié ; ASalarié := ACommissionné ; TCommissionedPtr := ACommissioned ; En général, la règle de compatibilité de type est formulée comme suit : la source doit pouvoir remplir complètement le récepteur. Les types dérivés contiennent tout ce que leurs types parents contiennent en raison de la propriété d'héritage. Par conséquent, le type dérivé a une taille non inférieure à la taille du parent. L'affectation d'un objet parent à un objet enfant pourrait laisser certains champs de l'objet parent indéfinis, ce qui est dangereux et donc illégal. Dans les instructions d'affectation, seuls les champs communs aux deux types seront copiés de la source vers la destination. Dans l'opérateur d'affectation : AnEmployee:= ACommissioned ; Seuls les champs Nom, Titre et Taux de ACommissioned seront copiés dans AnEmployee, car ce sont les seuls champs partagés entre TCommissioned et TEmployee. La compatibilité des types fonctionne également entre les pointeurs vers les types d'objets et suit les mêmes règles générales que pour les implémentations d'objets. Un pointeur vers un enfant peut être assigné à un pointeur vers le parent. Compte tenu des définitions précédentes, les affectations de pointeur suivantes sont valides : TSalariedPtr := TCommissionedPtr ; TEmployeePtr := TSalariedPtr ; TEmployeePtr := PCommissionedPtr ; Un paramètre formel (une valeur ou un paramètre variable) d'un type d'objet donné peut prendre comme paramètre réel un objet de son propre type ou des objets de tous les types enfants. Si vous définissez un en-tête de procédure comme celui-ci : procédure CalcFedTax(Victim: TSalaried); alors les types de paramètres réels peuvent être TSalaried ou TCommissioned, mais pas TEmployee. La victime peut également être un paramètre variable. Dans ce cas, les mêmes règles de compatibilité sont suivies. Le paramètre value est un pointeur vers l'objet réel envoyé en tant que paramètre, et le paramètre variable est une copie du paramètre réel. Cette copie inclut uniquement les champs qui font partie du type du paramètre de valeur formelle. Cela signifie que le paramètre réel est converti dans le type du paramètre formel. 37. À propos de l'assembleur Il était une fois, l'assembleur était un langage sans savoir lequel il était impossible de faire faire quoi que ce soit d'utile à un ordinateur. Peu à peu, la situation a changé. Des moyens de communication plus pratiques avec un ordinateur sont apparus. Mais contrairement à d'autres langages, l'assembleur n'est pas mort ; de plus, il ne pouvait pas le faire en principe. Pourquoi? A la recherche d'une réponse, nous allons essayer de comprendre ce qu'est le langage d'assemblage en général. En bref, le langage d'assemblage est une représentation symbolique du langage machine. Tous les processus de la machine au niveau matériel le plus bas ne sont pilotés que par des commandes (instructions) du langage machine. Il en ressort clairement que, malgré le nom commun, le langage d'assemblage de chaque type d'ordinateur est différent. Cela s'applique également à l'apparence des programmes écrits en assembleur et aux idées dont ce langage est le reflet. Résoudre réellement les problèmes liés au matériel (ou, plus encore, ceux liés au matériel, comme l'accélération d'un programme, par exemple) est impossible sans connaissance de l'assembleur. Un programmeur ou tout autre utilisateur peut utiliser n'importe quel outil de haut niveau jusqu'aux programmes de construction de mondes virtuels et, peut-être, ne même pas soupçonner que l'ordinateur exécute réellement non pas les commandes du langage dans lequel son programme est écrit, mais leur représentation transformée sous la forme d'une séquence ennuyeuse et ennuyeuse de commandes d'un langage complètement différent - le langage machine. Imaginez maintenant qu'un tel utilisateur ait un problème non standard. Par exemple, son programme doit fonctionner avec un appareil inhabituel ou effectuer d'autres actions nécessitant une connaissance des principes du matériel informatique. Quelle que soit la qualité du langage dans lequel le programmeur a écrit son programme, il ne peut se passer de connaître l'assembleur. Et ce n'est pas un hasard si presque tous les compilateurs de langages de haut niveau contiennent des moyens de connecter leurs modules avec des modules en assembleur ou prennent en charge l'accès au niveau de programmation assembleur. Un ordinateur est composé de plusieurs périphériques physiques, chacun connecté à une seule unité appelée unité centrale. 38. Modèle logiciel du microprocesseur Dans le marché informatique d'aujourd'hui, il existe une grande variété de différents types d'ordinateurs. Par conséquent, il est possible de supposer que le consommateur aura une question - comment évaluer les capacités d'un type (ou modèle) particulier d'un ordinateur et ses caractéristiques distinctives par rapport aux ordinateurs d'autres types (modèles). Considérer uniquement le schéma fonctionnel d'un ordinateur ne suffit pas pour cela, car il diffère fondamentalement peu d'une machine à l'autre : tous les ordinateurs ont de la RAM, un processeur et des périphériques externes. Différents sont les manières, les moyens et les ressources utilisées par lesquelles l'ordinateur fonctionne comme un mécanisme unique. Pour rassembler tous les concepts qui caractérisent un ordinateur en termes de propriétés fonctionnelles contrôlées par un programme, il existe un terme spécial - l'architecture informatique. Pour la première fois, le concept d'architecture informatique a commencé à être évoqué avec l'avènement des machines de 3ème génération pour leur évaluation comparative. Il est logique de commencer à apprendre le langage d'assemblage de n'importe quel ordinateur uniquement après avoir découvert quelle partie de l'ordinateur est laissée visible et disponible pour la programmation dans ce langage. C'est ce qu'on appelle le modèle de programme informatique, dont une partie est le modèle de programme du microprocesseur, qui contient 32 registres qui sont plus ou moins disponibles pour être utilisés par le programmeur. Ces registres peuvent être divisés en deux grands groupes : 1) 16 registres d'utilisateurs ; 2) 16 registres système. Les programmes en langage assembleur utilisent très fortement les registres. La plupart des registres ont un objectif fonctionnel spécifique. En plus des registres énumérés ci-dessus, les développeurs de processeurs introduisent des registres supplémentaires dans le modèle logiciel conçu pour optimiser certaines classes de calculs. Ainsi, dans la famille de processeurs Pentium Pro (MMX) d'Intel Corporation, l'extension MMX d'Intel a été introduite. Il comprend 8 registres 0 bits (MM7-MM64) et vous permet d'effectuer des opérations sur des nombres entiers sur des paires de plusieurs nouveaux types de données : 1) huit octets compressés ; 2) quatre mots emballés ; 3) deux mots doubles ; 4) mot quadruple ; En d'autres termes, avec une instruction d'extension MMX, le programmeur peut, par exemple, additionner deux mots doubles ensemble. Physiquement, aucun nouveau registre n'a été ajouté. MM0-MM7 sont les mantisses (64 bits inférieurs) d'une pile de registres FPU (unité à virgule flottante - coprocesseur) 80 bits. De plus, il existe actuellement les extensions suivantes du modèle de programmation - 3DNOW! d'AMD ; ESS, ESS2, ESS3, ESS4. Les 4 dernières extensions sont prises en charge par les processeurs AMD et Intel. 39. Registres des utilisateurs Comme leur nom l'indique, les registres d'utilisateurs sont appelés car le programmeur peut les utiliser lors de l'écriture de ses programmes. Ces registres comprennent : 1) huit registres 32 bits pouvant être utilisés par les programmeurs pour stocker des données et des adresses (ils sont également appelés registres à usage général (RON)) : ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ ebp/pb ; ▪ esi/si; ▪ edi/di; ▪ en particulier/sp. 2) registres à six segments : ▪ cs; ▪ ds; ▪ SS ; ▪ oui; ▪fs; ▪gs; 3) registres d'état et de contrôle : ▪ les drapeaux enregistrent les eflags/drapeaux ; ▪ Registre du pointeur de commande eip/ip. La figure suivante montre les principaux registres du microprocesseur : Registres à usage général
40. Registres généraux Tous les registres de ce groupe vous permettent d'accéder à leurs parties "inférieures". Seules les parties inférieures de 16 et 8 bits de ces registres peuvent être utilisées pour l'auto-adressage. Les 16 bits supérieurs de ces registres ne sont pas disponibles en tant qu'objets indépendants. Listons les registres appartenant au groupe des registres à usage général. Étant donné que ces registres sont physiquement situés dans le microprocesseur à l'intérieur de l'unité arithmétique et logique (ALU), ils sont également appelés registres ALU : 1) eax/ax/ah/al (registre d'accumulateur) - batterie. Utilisé pour stocker des données intermédiaires. Dans certaines commandes, l'utilisation de ce registre est obligatoire ; 2) ebx/bx/bh/bl (registre de base) - registre de base. Utilisé pour stocker l'adresse de base d'un objet en mémoire ; 3) ecx/cx/ch/cl (registre de comptage) - registre de compteur. Il est utilisé dans les commandes qui effectuent des actions répétitives. Son utilisation est souvent implicite et cachée dans l'algorithme de la commande correspondante. Par exemple, la commande d'organisation de boucle, en plus de transférer le contrôle à une commande située à une certaine adresse, analyse et décrémente de un la valeur du registre ecx/cx ; 4) edx/dx/dh/dl (registre de données) - registre de données. Tout comme le registre eax/ax/ah/al, il stocke des données intermédiaires. Certaines commandes nécessitent son utilisation ; pour certaines commandes, cela se produit implicitement. Les deux registres suivants sont utilisés pour prendre en charge les opérations dites en chaîne, c'est-à-dire des opérations qui traitent séquentiellement des chaînes d'éléments, dont chacune peut avoir une longueur de 32, 16 ou 8 bits : 1) esi/si (registre d'index source) - index source. Ce registre dans les opérations en chaîne contient l'adresse courante de l'élément dans la chaîne source ; 2) edi/di (registre d'index de destination) - index du destinataire (destinataire). Ce registre dans les opérations en chaîne contient l'adresse courante dans la chaîne de destination. Dans l'architecture du microprocesseur au niveau matériel et logiciel, une structure de données telle qu'une pile est supportée. Pour travailler avec la pile dans le système d'instructions du microprocesseur, il existe des commandes spéciales, et dans le modèle logiciel du microprocesseur, il existe des registres spéciaux pour cela: 1) esp/sp (registre de pointeur de pile) - registre de pointeur de pile. Contient un pointeur vers le haut de la pile dans le segment de pile actuel. 2) ebp/bp (registre de pointeur de base) - registre de pointeur de base de trame de pile. Conçu pour organiser un accès aléatoire aux données à l'intérieur de la pile. L'utilisation de l'épinglage dur des registres pour certaines instructions permet d'encoder leur représentation machine de manière plus compacte. La connaissance de ces fonctionnalités permettra, si nécessaire, d'économiser au moins quelques octets de mémoire occupés par le code du programme. 41. Registres de segments Il existe six registres de segments dans le modèle logiciel du microprocesseur : cs, ss, ds, es, gs, fs. Leur existence est due aux spécificités de l'organisation et de l'utilisation de la RAM par les microprocesseurs Intel. Elle réside dans le fait que le matériel du microprocesseur supporte l'organisation structurelle du programme sous la forme de trois parties, appelées segments. En conséquence, une telle organisation de la mémoire est dite segmentée. Afin d'indiquer les segments auxquels le programme a accès à un instant donné, des registres de segments sont prévus. En fait (avec une légère correction) ces registres contiennent les adresses mémoire à partir desquelles commencent les segments correspondants. La logique de traitement d'une instruction machine est construite de telle manière que les adresses dans des registres de segments bien définis sont implicitement utilisées lors de la récupération d'une instruction, de l'accès aux données du programme ou de l'accès à la pile. Le microprocesseur prend en charge les types de segments suivants. 1. Segment codé. Contient des commandes de programme. Pour accéder à ce segment, le registre cs (registre de segment de code) est utilisé - le registre de code de segment. Il contient l'adresse du segment avec les instructions machine auxquelles le microprocesseur a accès (c'est-à-dire que ces instructions sont chargées dans le pipeline du microprocesseur). 2. Segment de données. Contient les données traitées par le programme. Pour accéder à ce segment, le registre ds (registre de segment de données) est utilisé - un registre de données de segment qui stocke l'adresse du segment de données du programme en cours. 3. Segment de pile. Ce segment est une région de mémoire appelée la pile. Le microprocesseur organise le travail avec la pile selon le principe suivant : le dernier élément écrit dans cette zone est sélectionné en premier. Pour accéder à ce segment, le registre ss (registre de segment de pile) est utilisé - le registre de segment de pile contenant l'adresse du segment de pile. 4. Segment de données supplémentaire. Implicitement, les algorithmes d'exécution de la plupart des instructions machine supposent que les données qu'ils traitent se trouvent dans le segment de données dont l'adresse se trouve dans le registre du segment ds. Si le programme n'a pas assez d'un segment de données, il a la possibilité d'utiliser trois autres segments de données supplémentaires. Mais contrairement au segment de données principal, dont l'adresse est contenue dans le registre de segment ds, lors de l'utilisation de segments de données supplémentaires, leurs adresses doivent être spécifiées explicitement à l'aide de préfixes spéciaux de redéfinition de segment dans la commande. Les adresses des segments de données supplémentaires doivent être contenues dans les registres es, gs, fs (registres de segments de données d'extension). 42. Registres d'état et de contrôle Le microprocesseur comprend plusieurs registres qui contiennent en permanence des informations sur l'état à la fois du microprocesseur lui-même et du programme dont les instructions sont actuellement chargées sur le pipeline. Ces registres comprennent : 1) registre de drapeaux eflags/drapeaux ; 2) registre de pointeur de commande eip/ip. À l'aide de ces registres, vous pouvez obtenir des informations sur les résultats de l'exécution de la commande et influencer l'état du microprocesseur lui-même. Examinons plus en détail le but et le contenu de ces registres. 1. eflags/flags (registre des drapeaux) - registre des drapeaux. La profondeur de bits des eflags/flags est de 32/16 bits. Les bits individuels de ce registre ont un objectif fonctionnel spécifique et sont appelés drapeaux. La partie inférieure de ce registre est complètement similaire au registre des drapeaux pour i8086. Selon leur utilisation, les drapeaux du registre eflags/flags peuvent être divisés en trois groupes : 1) huit drapeaux d'état. Ces drapeaux peuvent changer après l'exécution des instructions machine. Les drapeaux d'état du registre eflags reflètent les spécificités du résultat de l'exécution d'opérations arithmétiques ou logiques. Cela permet d'analyser l'état du processus de calcul et d'y répondre à l'aide de commandes de saut conditionnel et d'appels de sous-programmes. 2) un drapeau de contrôle. Noté df (Directory Flag). Il est situé dans le bit 10 du registre eflags et est utilisé par les commandes chaînées. La valeur du drapeau df détermine le sens du traitement élément par élément dans ces opérations : du début de la chaîne à la fin (df = 0) ou inversement, de la fin de la chaîne à son début (df = 1). Il existe des commandes spéciales pour travailler avec le drapeau df : cld (supprimer le drapeau df) et std (définir le drapeau df). L'utilisation de ces commandes vous permet d'ajuster l'indicateur df conformément à l'algorithme et de garantir que les compteurs sont automatiquement incrémentés ou décrémentés lors de l'exécution d'opérations sur des chaînes. 3) cinq drapeaux système. Ils contrôlent les E/S, les interruptions masquables, le débogage, la commutation de tâches et le mode virtuel 8086. Il n'est pas recommandé aux programmes d'application de modifier ces indicateurs inutilement, car cela entraînera l'arrêt du programme dans la plupart des cas. 2. eip/ip (Instraction Pointer register) - registre de pointeur d'instruction. Le registre eip/ip a une largeur de 32/16 bits et contient le décalage de la prochaine instruction à exécuter par rapport au contenu du registre de segment cs dans le segment d'instruction courant. Ce registre n'est pas directement accessible au programmeur, mais sa valeur est chargée et modifiée par diverses commandes de contrôle, qui incluent des commandes de sauts conditionnels et inconditionnels, d'appel de procédures et de retour de procédures. L'apparition d'interruptions modifie également le registre eip/ip. 43. Registres du système à microprocesseur Le nom même de ces registres suggère qu'ils remplissent des fonctions spécifiques dans le système. L'utilisation des registres du système est strictement réglementée. Ce sont eux qui assurent le mode protégé. Ils peuvent également être considérés comme faisant partie de l'architecture du microprocesseur, qui est délibérément laissée visible afin qu'un programmeur système qualifié puisse effectuer les opérations les plus élémentaires. Les registres système peuvent être divisés en trois groupes : 1) quatre registres de contrôle ; Le groupe de registres de contrôle comprend 4 registres : ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) quatre registres d'adresses système (également appelés registres de gestion de mémoire) ; Les registres d'adresses système comprennent les registres suivants : ▪ registre de table de descripteurs global gdtr ; ▪ registre de table de descripteurs locaux Idtr ; ▪ registre de la table des descripteurs d'interruption idtr ; ▪ Registre de tâches tr 16 bits ; 3) huit registres de débogage. Ceux-ci inclus: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ Dr7. La connaissance des registres système n'est pas nécessaire pour écrire des programmes en assembleur, du fait qu'ils sont principalement utilisés pour les opérations les plus bas niveau. Cependant, les tendances actuelles dans le développement de logiciels (en particulier à la lumière des capacités d'optimisation considérablement accrues des compilateurs modernes de langages de haut niveau, qui génèrent souvent du code dont l'efficacité est supérieure au code humain) réduisent la portée d'Assembler à la résolution des problèmes les plus bas. -problèmes de niveau, où la connaissance des registres ci-dessus peut s'avérer très utile. 44. Registres de contrôle Le groupe de registres de contrôle comprend quatre registres : cr0, cr1, cr2, cr3. Ces registres sont destinés au contrôle général du système. Les registres de contrôle ne sont disponibles que pour les programmes avec le niveau de privilège 0. Bien que le microprocesseur dispose de quatre registres de contrôle, seuls trois d'entre eux sont disponibles - cr1 est exclu, dont les fonctions ne sont pas encore définies (il est réservé à une utilisation future). Le registre cr0 contient des indicateurs système qui contrôlent les modes de fonctionnement du microprocesseur et reflètent son état globalement, quelles que soient les tâches spécifiques en cours d'exécution. Objectif des drapeaux système : 1) pe (Protect Enable), bit 0 - active le mode protégé. L'état de ce drapeau indique dans lequel des deux modes - réel (pe = 0) ou protégé (pe = 1) - le microprocesseur fonctionne à un instant donné ; 2) mp (Math Present), bit 1 - la présence d'un coprocesseur. Toujours 1 ; 3) ts (Task Switched), bit 3 - commutation de tâche. Le processeur positionne automatiquement ce bit lorsqu'il passe à une autre tâche ; 4) am (masque d'alignement), bit 18 - masque d'alignement. Ce bit active (am = 1) ou désactive (am = 0) la commande d'alignement ; 5) cd (Cache Disable), bit 30 - désactive la mémoire cache. A l'aide de ce bit, vous pouvez désactiver (cd = 1) ou activer (cd = 0) l'utilisation du cache interne (le cache de premier niveau) ; 6) pg (PaGing), bit 31 - activer (pg = 1) ou désactiver (pg = 0) la pagination. Le drapeau est utilisé dans le modèle de pagination de l'organisation de la mémoire. Le registre cr2 est utilisé dans la pagination RAM pour enregistrer la situation lorsque l'instruction en cours a accédé à l'adresse contenue dans une page mémoire qui n'est actuellement pas en mémoire. Dans une telle situation, un numéro d'exception 14 se produit dans le microprocesseur, et l'adresse linéaire de 32 bits de l'instruction qui a provoqué cette exception est écrite dans le registre cr2. Avec ces informations, le gestionnaire d'exceptions 14 détermine la page souhaitée, l'échange en mémoire et reprend le fonctionnement normal du programme ; Le registre cr3 est également utilisé pour la pagination de la mémoire. C'est ce que l'on appelle le registre de répertoire de pages de premier niveau. Il contient l'adresse de base physique 20 bits du répertoire de pages de la tâche en cours. Ce répertoire contient 1024 descripteurs 32 bits, chacun contenant l'adresse de la table de pages de second niveau. À leur tour, chacune des tables de pages de second niveau contient 1024 descripteurs 32 bits qui adressent des cadres de page en mémoire. La taille du cadre de page est de 4 Ko. 45. Registres des adresses système Ces registres sont également appelés registres de gestion de la mémoire. Ils sont conçus pour protéger les programmes et les données dans le mode multitâche du microprocesseur. Lors du fonctionnement en mode protégé par microprocesseur, l'espace d'adressage est divisé en : 1) global - commun à toutes les tâches ; 2) local - séparé pour chaque tâche. Cette division explique la présence des registres système suivants dans l'architecture du microprocesseur : 1) le registre de la table de descripteurs globaux gdtr (Global Descriptor Table Register), ayant une taille de 48 bits et contenant une adresse de base de 32 bits (bits 16-47) de la table de descripteurs globaux GDT et une adresse de base de 16 bits (bits 0-15) valeur limite, qui est la taille en octets de la table GDT ; 2) le registre de table de descripteurs locaux ldtr (Local Descriptor Table Register), d'une taille de 16 bits et contenant le dit sélecteur de descripteurs de la table de descripteurs locaux LDT. Ce sélecteur est un pointeur vers le GDT qui décrit le segment contenant la table de descripteurs locaux LDT ; 3) le registre de la table de descripteurs d'interruptions idtr (Interrupt Descriptor Table Register), d'une taille de 48 bits et contenant une adresse de base de 32 bits (bits 16-47) de la table de descripteurs d'interruptions IDT et une adresse de base de 16 bits (bits 0-15) valeur limite, qui est la taille en octets de la table IDT ; 4) le registre de tâches 16 bits tr (Task Register), qui, comme le registre ldtr, contient un sélecteur, c'est-à-dire un pointeur vers un descripteur dans la table GDT. Ce descripteur décrit l'état actuel du segment de tâche (TSS). Ce segment est créé pour chaque tâche du système, a une structure strictement réglementée et contient le contexte (état actuel) de la tâche. L'objectif principal des segments TSS est de sauvegarder l'état actuel d'une tâche au moment du passage à une autre tâche. 46. Registres de débogage Il s'agit d'un groupe de registres très intéressant destiné au débogage matériel. Les outils de débogage matériel sont apparus pour la première fois dans le microprocesseur i486. Dans le matériel, le microprocesseur contient huit registres de débogage, mais seuls six d'entre eux sont réellement utilisés. Les registres dr0, dr1, dr2, dr3 ont une largeur de 32 bits et sont conçus pour définir les adresses linéaires de quatre points d'arrêt. Le mécanisme utilisé dans ce cas est le suivant : toute adresse générée par le programme en cours est comparée aux adresses des registres dr0... dr3, et s'il y a une correspondance, une exception de débogage avec le numéro 1 est générée. Le registre dr6 est appelé le registre d'état de débogage. Les bits de ce registre sont définis en fonction des raisons qui ont provoqué l'apparition de la dernière exception numéro 1. Nous listons ces bits et leur but: 1) b0 - si ce bit est mis à 1, la dernière exception (interruption) s'est produite suite à l'atteinte du point de contrôle défini dans le registre dr0 ; 2) b1 - similaire à b0, mais pour un point de contrôle dans le registre dr1 ; 3) b2 - similaire à b0, mais pour un point de contrôle dans le registre dr2 ; 4) b3 - similaire à b0, mais pour un point de contrôle dans le registre dr3 ; 5) bd (bit 13) - sert à protéger les registres de débogage ; 6) bs (bit 14) - mis à 1 si l'exception 1 a été provoquée par l'état du drapeau tf = 1 dans le registre eflags ; 7) bt (bit 15) est mis à 1 si l'exception 1 a été provoquée par un passage à une tâche avec le bit de piège défini dans TSS t = 1. Tous les autres bits de ce registre sont remplis de zéros. Le gestionnaire d'exceptions 1, basé sur le contenu de dr6, doit déterminer la raison pour laquelle l'exception s'est produite et prendre les mesures nécessaires. Le registre dr7 est appelé le registre de contrôle de débogage. Il contient des champs pour chacun des quatre registres de point d'arrêt de débogage qui vous permettent de spécifier les conditions suivantes dans lesquelles une interruption doit être générée : 1) emplacement d'enregistrement du point de contrôle - uniquement dans la tâche en cours ou dans n'importe quelle tâche. Ces bits occupent les 8 bits inférieurs du registre dr7 (2 bits pour chaque point d'arrêt (en fait un point d'arrêt) défini par les registres dr0, drl, dr2, dr3, respectivement). Le premier bit de chaque paire est la résolution dite locale ; le définir indique au point d'arrêt de prendre effet s'il se trouve dans l'espace d'adressage de la tâche en cours. Le deuxième bit de chaque paire spécifie l'autorisation globale, qui indique que le point d'arrêt donné est valide dans les espaces d'adressage de toutes les tâches du système ; 2) le type d'accès par lequel l'interruption est initiée : uniquement lors de la récupération d'une commande, lors de l'écriture ou lors de l'écriture/lecture de données. Les bits qui déterminent cette nature d'occurrence d'une interruption sont situés dans la partie supérieure de ce registre. La plupart des registres système sont accessibles par programmation. 47. La structure du programme en assembleur Un programme en langage assembleur est un ensemble de blocs de mémoire appelés segments de mémoire. Un programme peut consister en un ou plusieurs de ces blocs-segments. Chaque segment contient une collection de phrases de langage, dont chacune occupe une ligne distincte de code de programme. Les instructions d'assemblage sont de quatre types. Commandes ou instructions qui sont les équivalents symboliques des instructions machine. Au cours du processus de traduction, les instructions d'assemblage sont converties en commandes correspondantes du jeu d'instructions du microprocesseur. Une instruction Assembleur correspond en règle générale à une instruction microprocesseur, ce qui, en général, est typique des langages de bas niveau. Voici un exemple d'instruction qui incrémente de un le nombre binaire stocké dans le registre eax : inc. ▪ macrocommandes - phrases du texte du programme formatées d'une certaine manière, remplacées lors de la diffusion par d'autres phrases. Un exemple de macro est la macro de fin de programme suivante : macro de sortie movax, 4c00h Int 21h finm ▪ les directives, qui sont des instructions adressées au traducteur assembleur pour effectuer certaines actions. Les directives n'ont pas d'équivalent dans la représentation machine ; A titre d'exemple, voici la directive TITLE qui définit le titre du fichier listing : %TITLE "Listing 1" ▪ lignes de commentaires contenant tous les caractères, y compris les lettres de l'alphabet russe. Les commentaires sont ignorés par le traducteur. Exemple: ; cette ligne est un commentaire 48. Syntaxe d'assemblage Les phrases qui composent un programme peuvent être une construction syntaxique correspondant à une commande, une macro, une directive ou un commentaire. Pour que le traducteur assembleur les reconnaisse, ils doivent être formés selon certaines règles syntaxiques. Pour ce faire, il est préférable d'utiliser une description formelle de la syntaxe du langage, comme les règles de grammaire. Les façons les plus courantes de décrire un langage de programmation de cette manière sont les diagrammes de syntaxe et les formes Backus-Naur étendues. Lorsque vous travaillez avec des diagrammes de syntaxe, faites attention au sens de parcours, indiqué par les flèches. Les diagrammes de syntaxe reflètent la logique du traducteur lors de l'analyse des phrases d'entrée du programme. Caractères valides : 1) toutes les lettres latines : A - Z, a - z ; 2) nombres de 0 à 9 ; 3) signes ? @, $, & ; 4) séparateurs. Les jetons sont les suivants. 1. Identificateurs - séquences de caractères valides utilisées pour désigner les codes d'opération, les noms de variable et les noms d'étiquette. Un identifiant ne peut pas commencer par un chiffre. 2. Chaînes de caractères - séquences de caractères entre guillemets simples ou doubles. 3. Nombres entiers. Types d'instructions assembleur possibles. 1. Opérateurs arithmétiques. Ceux-ci inclus: 1) "+" et "-" unaires ; 2) "+" et "-" binaires ; 3) multiplier "*" ; 4) division entière "/" ; 5) obtenir le reste de la division "mod". 2. Les opérateurs de décalage décalent l'expression du nombre de bits spécifié. 3. Les opérateurs de comparaison (retour "vrai" ou "faux") sont conçus pour former des expressions logiques. 4. Les opérateurs logiques effectuent des opérations au niveau du bit sur les expressions. 5. Opérateur d'index []. 6. L'opérateur de redéfinition de type ptr est utilisé pour redéfinir ou qualifier le type d'une étiquette ou d'une variable définie par une expression. 7. L'opérateur de redéfinition de segment ":" (deux-points) entraîne le calcul de l'adresse physique par rapport au composant de segment spécifié. 8. Opérateur de dénomination de type de structure "." (point) oblige également le compilateur à effectuer certains calculs s'il se produit dans une expression. 9. L'opérateur pour obtenir le composant de segment de l'adresse de l'expression seg renvoie l'adresse physique du segment pour l'expression, qui peut être une étiquette, une variable, un nom de segment, un nom de groupe ou un nom symbolique. 10. L'opérateur d'obtention de l'offset de l'expression offset permet d'obtenir la valeur de l'offset de l'expression en octets par rapport au début du segment dans lequel l'expression est définie. 49. Directives de segmentation La segmentation fait partie d'un mécanisme plus général lié au concept de programmation modulaire. Cela implique l'unification de la conception des modules objets créés par le compilateur, y compris ceux de différents langages de programmation. Cela vous permet de combiner des programmes écrits dans différentes langues. C'est à la mise en œuvre de diverses options pour une telle union que les opérandes de la directive SEGMENT sont destinés. Laissez-nous les examiner plus en détail. 1. L'attribut d'alignement de segment (type d'alignement) indique à l'éditeur de liens de s'assurer que le début du segment est placé sur la limite spécifiée : 1) BYTE - l'alignement n'est pas effectué ; 2) WORD - le segment commence à une adresse qui est un multiple de deux, c'est-à-dire que le dernier bit (le moins significatif) de l'adresse physique est 0 (aligné sur la limite du mot); 3) DWORD - le segment commence à une adresse qui est un multiple de quatre ; 4) PARA - le segment commence à une adresse qui est un multiple de 16 ; 5) PAGE - le segment commence à une adresse qui est un multiple de 256 ; 6) MEMPAGE - le segment commence à une adresse qui est un multiple de 4 Ko. 2. L'attribut combine segment (type combinatoire) indique à l'éditeur de liens comment combiner des segments de différents modules portant le même nom : 1) PRIVÉ - le segment ne sera pas fusionné avec d'autres segments portant le même nom en dehors de ce module ; 2) PUBLIC - force l'éditeur de liens à connecter tous les segments avec le même nom ; 3) COMMUN - a tous les segments avec le même nom à la même adresse ; 4) AT xxxx - localise le segment à l'adresse absolue du paragraphe ; 5) STACK - définition d'un segment de pile. 3. Un attribut de classe de segment (type de classe) est une chaîne entre guillemets qui aide l'éditeur de liens à déterminer l'ordre de segment approprié lors de l'assemblage d'un programme à partir de plusieurs segments de module. 4. Attribut de taille de segment : 1) USE16 - cela signifie que le segment permet un adressage 16 bits ; 2) USE32 - le segment sera de 32 bits. Il doit y avoir un moyen de compenser l'impossibilité. contrôler directement le placement et la combinaison des segments. Pour ce faire, ils ont commencé à utiliser la directive pour spécifier le modèle de mémoire MODEL. Cette directive lie les segments, qui dans le cas de l'utilisation de directives de segmentation simplifiées, ont des noms prédéfinis, avec des registres de segment (bien que vous deviez toujours initialiser explicitement ds). Le paramètre obligatoire de la directive MODEL est le modèle de mémoire. Ce paramètre définit le modèle de segmentation de la mémoire pour le POU. On suppose qu'un module de programme ne peut avoir que certains types de segments, qui sont définis par les directives simplifiées de description de segment que nous avons mentionnées précédemment. 50. Structure des instructions de la machine Une commande machine est une indication au microprocesseur, codée selon certaines règles, d'effectuer une opération ou une action. Chaque commande contient des éléments qui définissent : 1) que faire ? 2) objets sur lesquels quelque chose doit être fait (ces éléments sont appelés opérandes) ; 3) comment faire ? La longueur maximale d'une instruction machine est de 15 octets. 1. Préfixes. Éléments d'instruction machine facultatifs, dont chacun est de 1 octet ou peut être omis. En mémoire, les préfixes précèdent la commande. Le but des préfixes est de modifier l'opération effectuée par la commande. Une application peut utiliser les types de préfixes suivants : 1) préfixe de remplacement de segment ; 2) le préfixe de longueur en bits de l'adresse spécifie la longueur en bits de l'adresse (32 bits ou 16 bits); 3) le préfixe de longueur en bits de l'opérande est similaire au préfixe de longueur en bits de l'adresse, mais indique la longueur en bits de l'opérande (32 bits ou 16 bits) avec laquelle la commande fonctionne ; 4) Le préfixe de répétition est utilisé avec les commandes chaînées. 2. Code d'opération. Élément obligatoire qui décrit l'opération effectuée par la commande. 3. Mode d'adressage octet modr/m. La valeur de cet octet détermine la forme d'adresse d'opérande utilisée. Les opérandes peuvent être en mémoire dans un ou deux registres. Si l'opérande est en mémoire, alors l'octet modr/m spécifie les composants (registres d'offset, de base et d'index) utilisé pour calculer son adresse effective. L'octet modr/m se compose de trois champs : 1) le champ mod détermine le nombre d'octets occupés dans l'instruction par l'adresse de l'opérande ; 2) le champ reg/cop détermine soit le registre situé dans la commande à la place du premier opérande, soit une éventuelle extension de l'opcode ; 3) le champ r/m est utilisé conjointement avec le champ mod et détermine soit le registre situé dans la commande à la place du premier opérande (si mod = 11), soit les registres de base et d'index utilisés pour calculer l'adresse effective (avec le champ offset dans la commande). 4. Échelle d'octets - index - base (byte sib). Permet d'étendre les possibilités d'adressage des opérandes. L'octet sib se compose de trois champs : 1) ss champs d'échelle. Ce champ contient le facteur d'échelle pour l'indice de composant d'index, qui occupe les 3 bits suivants de l'octet sib ; 2) champs d'index. Utilisé pour stocker le numéro de registre d'index utilisé pour calculer l'adresse effective de l'opérande ; 3) champs de base. Utilisé pour stocker le numéro de registre de base, qui est également utilisé pour calculer l'adresse effective de l'opérande. 5. Champ de décalage dans la commande. Entier signé de 8, 16 ou 32 bits représentant, en tout ou en partie (sous réserve des considérations ci-dessus), la valeur de l'adresse effective de l'opérande. 6. Le champ de l'opérande immédiat. Un champ facultatif représentant 8-, Opérande immédiat 16 ou 32 bits. La présence de ce champ est bien entendu reflétée dans la valeur de l'octet modr/m. 51. Méthodes de spécification des opérandes d'instruction L'opérande est défini implicitement au niveau du firmware Dans ce cas, l'instruction ne contient explicitement aucun opérande. L'algorithme d'exécution de la commande utilise certains objets par défaut (registres, drapeaux dans eflags, etc.). L'opérande est spécifié dans l'instruction elle-même (opérande immédiat) L'opérande est dans le code d'instruction, c'est-à-dire qu'il en fait partie. Pour stocker un tel opérande, un champ d'une longueur maximale de 32 bits est alloué dans l'instruction. L'opérande immédiat ne peut être que le second opérande (source). L'opérande de destination peut être en mémoire ou dans un registre. L'opérande se trouve dans l'un des registres. Les opérandes de registre sont spécifiés par des noms de registre. Les registres peuvent être utilisés : 1) registres 32 bits EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP ; 2) registres 16 bits AX, BX, CX, DX, SI, DI, SP, BP ; 3) registres 8 bits AH, AL, BH, BL, CH, CL, DH, DL ; 4) registres de segments CS, DS, SS, ES, FS, GS. Par exemple, la commande add ax,bx ajoute le contenu des registres ax et bx et écrit le résultat dans bx. La commande dec si décrémente le contenu de si de 1. L'opérande est en mémoire C'est la manière la plus complexe et en même temps la plus flexible de spécifier des opérandes. Il permet de mettre en œuvre les deux principaux types d'adressage suivants : direct et indirect. À son tour, l'adressage indirect a les variétés suivantes : 1) adressage de base indirect ; son autre nom est registre d'adressage indirect ; 2) adressage de base indirect avec décalage; 3) adressage d'index indirect avec décalage ; 4) adressage d'index de base indirect ; 5) adressage d'index de base indirect avec décalage. L'opérande est un port d'E/S En plus de l'espace d'adressage RAM, le microprocesseur maintient un espace d'adressage d'E/S, qui est utilisé pour accéder aux dispositifs d'E/S. L'espace d'adressage d'E/S est de 64 Ko. Des adresses sont attribuées pour tout dispositif informatique dans cet espace. Une valeur d'adresse particulière dans cet espace est appelée un port d'E/S. Physiquement, le port d'E / S correspond à un registre matériel (à ne pas confondre avec un registre de microprocesseur), auquel on accède à l'aide d'instructions assembleur spéciales in et out. L'opérande est sur la pile Les instructions peuvent n'avoir aucun opérande, peuvent avoir un ou deux opérandes. La plupart des instructions nécessitent deux opérandes, dont l'un est l'opérande source et l'autre est l'opérande de destination. Il est important qu'un opérande puisse être situé dans un registre ou une mémoire, et que le deuxième opérande soit dans un registre ou directement dans l'instruction. Un opérande immédiat ne peut être qu'un opérande source. Dans une instruction machine à deux opérandes, les combinaisons d'opérandes suivantes sont possibles : 1) registre - registre; 2) registre - mémoire ; 3) mémoire - registre ; 4) opérande immédiat - registre ; 5) opérande immédiat - mémoire. 52. Modes d'adressage Adressage direct Il s'agit de la forme la plus simple d'adressage d'un opérande en mémoire, puisque l'adresse effective est contenue dans l'instruction elle-même et qu'aucune source ou registre supplémentaire n'est utilisé pour la former. L'adresse effective est tirée directement du champ de décalage de l'instruction machine, qui peut être de 8, 16 ou 32 bits. Cette valeur identifie de manière unique l'octet, le mot ou le double mot situé dans le segment de données. L'adressage direct peut être de deux types. Adressage direct relatif Utilisé pour les instructions de saut conditionnel pour indiquer l'adresse de saut relative. La relativité d'une telle transition réside dans le fait que le champ de décalage de l'instruction machine contient une valeur de 8, 16 ou 32 bits qui, à la suite du fonctionnement de l'instruction, sera ajoutée au contenu de le registre de pointeur d'instruction ip/eip. À la suite de cet ajout, l'adresse est obtenue, à laquelle la transition est effectuée. Adressage direct absolu Dans ce cas, l'adresse effective fait partie de l'instruction machine, mais cette adresse n'est formée que de la valeur du champ offset dans l'instruction. Pour former l'adresse physique de l'opérande en mémoire, le microprocesseur additionne ce champ avec la valeur du registre segment décalé de 4 bits. Plusieurs formes de cet adressage peuvent être utilisées dans une instruction assembleur. Adressage de base indirect (registre) Avec cet adressage, l'adresse effective de l'opérande peut être dans n'importe lequel des registres à usage général, à l'exception de sp / esp et bp / ebp (ce sont des registres spécifiques pour travailler avec un segment de pile). Syntaxiquement, dans une commande, ce mode d'adressage est exprimé en mettant le nom du registre entre crochets []. Adressage indirect de base (registre) avec décalage Ce type d'adressage s'ajoute au précédent et est conçu pour accéder aux données avec un décalage connu par rapport à une adresse de base. Ce type d'adressage est pratique à utiliser pour accéder aux éléments des structures de données, lorsque le décalage des éléments est connu à l'avance, au stade du développement du programme, et que l'adresse de base (de départ) de la structure doit être calculée dynamiquement, au stade d'exécution du programme. Adressage d'index indirect avec décalage Ce type d'adressage est très similaire à l'adressage de base indirect avec un décalage. Ici aussi, l'un des registres à usage général est utilisé pour former l'adresse effective. Mais l'adressage d'index a une fonctionnalité intéressante qui est très pratique pour travailler avec des tableaux. Il est lié à la possibilité de la soi-disant mise à l'échelle du contenu du registre d'index. Adressage d'index de base indirect Avec ce type d'adressage, l'adresse effective est formée comme la somme du contenu de deux registres à usage général : base et index. Ces registres peuvent être n'importe quel registre à usage général, et la mise à l'échelle du contenu d'un registre d'index est souvent utilisée. Adressage d'index de base indirect avec décalage Ce type d'adressage est le complément de l'adressage indexé indirect. L'adresse effective est formée comme la somme de trois composants : le contenu du registre de base, le contenu du registre d'index et la valeur du champ de décalage dans la commande. 53. Commandes de transfert de données Commandes générales de transfert de données Ce groupe comprend les commandes suivantes : 1) mov est la commande principale de transfert de données ; 2) xchg - utilisé pour le transfert de données bidirectionnel. Commandes d'E/S de port Fondamentalement, la gestion des appareils directement via les ports est simple : 1) dans l'accumulateur, numéro de port - entrée dans l'accumulateur à partir du port avec le numéro de port ; 2) port de sortie, accumulateur - envoie le contenu de l'accumulateur au port avec le numéro de port. Commandes de conversion de données De nombreuses instructions de microprocesseur peuvent être attribuées à ce groupe, mais la plupart d'entre elles ont certaines caractéristiques qui nécessitent qu'elles soient attribuées à d'autres groupes fonctionnels. Commandes de pile Ce groupe est un ensemble de commandes spécialisées axées sur l'organisation d'un travail flexible et efficace avec la pile. La pile est une zone de mémoire spécialement allouée au stockage temporaire des données du programme. Il existe trois registres pour travailler avec la pile : 1) ss - registre de segment de pile ; 2) sp/esp - registre de pointeur de pile ; 3) bp/ebp - registre de pointeur de base de cadre de pile. Pour organiser le travail avec la pile, il existe des commandes spéciales pour l'écriture et la lecture. 1. pousser la source - écrire la valeur source en haut de la pile. 2. affectation pop - écriture de la valeur du haut de la pile à l'emplacement indiqué par l'opérande de destination. La valeur est ainsi "supprimée" du haut de la pile. 3. pusha - une commande d'écriture de groupe sur la pile. 4. pushaw est presque synonyme de la commande pusha. L'attribut bitness peut être use16 ou use32. R 5. pushad - exécuté de la même manière que la commande pusha, mais il y a quelques particularités. Les trois commandes suivantes effectuent l'inverse des commandes ci-dessus : 1) popa ; 2) popaw ; 3) sauter. Le groupe d'instructions décrit ci-dessous permet de sauvegarder le registre des drapeaux sur la pile et d'écrire un mot ou un double mot dans la pile. 1. pushf - enregistre le registre des drapeaux sur la pile. 2. pushfw - enregistrement d'un registre d'indicateurs de la taille d'un mot sur la pile. Fonctionne toujours comme pushf avec l'attribut use16. 3. pushfd - enregistre le registre des drapeaux flags ou eflags sur la pile en fonction de l'attribut de largeur en bits du segment (c'est-à-dire, le même que pushf). De même, les trois commandes suivantes effectuent l'inverse des opérations décrites ci-dessus : 1) popf ; 2) popfw ; 3) popfd. 54. Commandes arithmétiques Ces commandes fonctionnent avec deux types : 1) nombres binaires entiers, c'est-à-dire avec des nombres codés dans le système de nombre binaire. Les nombres décimaux sont un type particulier de représentation des informations numériques, qui repose sur le principe du codage de chaque chiffre décimal d'un nombre par un groupe de quatre bits. Le microprocesseur effectue l'addition des opérandes selon les règles d'addition des nombres binaires. Il existe trois instructions d'addition binaires dans le jeu d'instructions du microprocesseur : 1) inc opérande - augmente la valeur de l'opérande ; 2) ajouter opérande1, opérande2 - addition ; 3) adc operand1, operand2 - ajout, en tenant compte du drapeau de portage cf. Soustraction de nombres binaires non signés Si la diminution est supérieure à la diminution, alors la différence est positive. Si la diminution est inférieure à la soustraction, il y a un problème : le résultat est inférieur à 0, et c'est déjà un nombre signé. Après avoir soustrait les nombres non signés, vous devez analyser l'état du drapeau CF. S'il est mis à 1, alors le bit le plus significatif a été emprunté et le résultat est dans le code de complément à deux. Soustraction de nombres binaires avec un signe Mais pour la soustraction par addition de nombres avec un signe dans un code supplémentaire, il est nécessaire de représenter les deux opérandes - à la fois la diminution et la soustraction. Le résultat doit également être traité comme une valeur de complément à deux. Mais ici les difficultés surgissent. Tout d'abord, ils sont liés au fait que le bit de poids fort de l'opérande est considéré comme un bit de signe. Selon le contenu de l'indicateur de débordement de. Le définir sur 1 indique que le résultat est hors de la plage des nombres signés (c'est-à-dire que le bit le plus significatif a changé) pour un opérande de cette taille, et le programmeur doit prendre des mesures pour corriger le résultat. Le principe de soustraction de nombres avec une plage de représentation dépassant les grilles de bits standard des opérandes est le même que pour l'addition, c'est-à-dire que l'indicateur de retenue cf est utilisé. Il vous suffit d'imaginer le processus de soustraction dans une colonne et de combiner correctement les instructions du microprocesseur avec l'instruction sbb. La commande pour multiplier les nombres non signés est facteur multiple_1 La commande pour multiplier les nombres par un signe est [imul opérande_1, opérande_2, opérande_3] La commande div diviseur sert à diviser des nombres non signés. La commande idiv diviseur sert à diviser les nombres signés. 55. Commandes logiques Selon la théorie, les opérations logiques suivantes peuvent être effectuées sur des instructions (sur des bits). 1. Négation (NON logique) - une opération logique sur un opérande, dont le résultat est l'inverse de la valeur de l'opérande d'origine. 2. Addition logique (OU inclusif logique) - une opération logique sur deux opérandes, dont le résultat est "vrai" (1) si l'un ou les deux opérandes sont vrais (1) et "faux" (0) si les deux opérandes sont faux (0). 3. Multiplication logique (ET logique) - une opération logique sur deux opérandes, dont le résultat est vrai (1) uniquement si les deux opérandes sont vrais (1). Dans tous les autres cas, la valeur de l'opération est "faux" (0). 4. Addition exclusive logique (OU exclusif logique) - une opération logique sur deux opérandes, dont le résultat est "vrai" (1), si un seul des deux opérandes est vrai (1) et faux (0), si les deux opérandes sont faux (0) ou vrais (1). 4. Addition exclusive logique (OU exclusif logique) - une opération logique sur deux opérandes, dont le résultat est "vrai" (1), si un seul des deux opérandes est vrai (1) et faux (0), si les deux opérandes sont faux (0) ou vrais (1). L'ensemble de commandes suivant qui prend en charge l'utilisation de données logiques : 1) et opérande_1, opérande_2 - opération de multiplication logique ; 2) ou opérande_1, opérande_2 - opération d'addition logique ; 3) xor operand_1, operand_2 - opération d'addition exclusive logique ; 4) test opérande_1, opérande_2 - opération "test" (par multiplication logique) 5) non opérande - opération de négation logique. a) pour mettre certains chiffres (bits) à 1, la commande ou opérande_1, opérande_2 est utilisée ; b) pour réinitialiser certains chiffres (bits) à 0, la commande et opérande_1, opérande_2 est utilisée ; c) la commande xor operand_1, operand_2 est appliquée : ▪ pour savoir quels bits de operand_1 et operand_2 sont différents ; ▪ inverser l'état des bits spécifiés en opérande_1. La commande test operand_1, operand_2 (check operand_1) permet de vérifier l'état des bits spécifiés. Le résultat de la commande est de définir la valeur du drapeau zéro zf : 1) si zf = 0, alors à la suite de la multiplication logique, un résultat nul a été obtenu, c'est-à-dire un bit unitaire du masque, qui ne correspondait pas au bit unitaire correspondant de l'opérande 1 ; 2) si zf = 1, alors la multiplication logique a abouti à un résultat non nul, c'est-à-dire qu'au moins un bit unitaire du masque a coïncidé avec le bit correspondant de l'opérande1. Toutes les instructions de décalage déplacent les bits du champ d'opérande vers la gauche ou la droite en fonction de l'opcode. Toutes les instructions de décalage ont la même structure : opérande de flic, compteur de décalage. 56. Commandes de transfert de contrôle Quelle instruction de programme doit être exécutée ensuite, le microprocesseur apprend à partir du contenu de la paire de registres cs: (e) ip : 1) cs - registre de segment de code, qui contient l'adresse physique du segment de code actuel ; 2) eip/ip - registre de pointeur d'instruction, il contient la valeur de décalage en mémoire de la prochaine instruction à exécuter. Sauts inconditionnels Ce qui doit être modifié dépend de : 1) sur le type d'opérande dans l'instruction de branchement inconditionnel (proche ou loin) ; 2) de spécifier un modificateur avant l'adresse de transition ; dans ce cas, l'adresse de saut elle-même peut être soit directement dans l'instruction (saut direct), soit dans un registre de mémoire (saut indirect). Valeurs du modificateur : 1) près de ptr - transition directe vers l'étiquette; 2) far ptr - transition directe vers une étiquette dans un autre segment de code ; 3) mot ptr - transition indirecte vers l'étiquette; 4) dword ptr - transition indirecte vers une étiquette dans un autre segment de code. instruction de saut inconditionnel jmp jmp [modificateur] jump_address Une procédure ou un sous-programme est l'unité fonctionnelle de base de la décomposition d'une tâche. Une procédure est un groupe de commandes. Sauts conditionnels Le microprocesseur dispose de 18 instructions de saut conditionnel. Ces commandes permettent de vérifier : 1) la relation entre les opérandes signés (« plus c'est moins ») ; 2) relation entre opérandes non signés ("supérieur inférieur"); 3) états des drapeaux arithmétiques ZF, SF, CF, OF, PF (mais pas AF). Les instructions de saut conditionnel ont la même syntaxe : jcc jump label La commande cmp compare a une façon intéressante de fonctionner. C'est exactement la même chose que la commande de soustraction - sous opérande_1, opérande_2. La commande cmp, comme la commande sub, soustrait des opérandes et définit des drapeaux. La seule chose qu'il ne fait pas est d'écrire le résultat de la soustraction à la place du premier opérande. La syntaxe de la commande cmp - cmp operand_1, operand_2 (comparer) - compare deux opérandes et définit des indicateurs en fonction des résultats de la comparaison. Organisation des cycles Vous pouvez organiser l'exécution cyclique d'une certaine section du programme, par exemple en utilisant le transfert conditionnel des commandes de contrôle ou la commande de saut inconditionnel jmp : 1) étiquette de transition de boucle (Loop) - répète la boucle. La commande permet d'organiser des boucles similaires aux boucles for dans les langages de haut niveau avec décrémentation automatique du compteur de boucle ; 2) étiquette de saut loope/loopz Les commandes loope et loopz sont des synonymes absolus ; 3) étiquette de saut loopne/loopnz Les commandes loopne et loopnz sont également des synonymes absolus. Les commandes loope/loopz et loopne/loopnz sont mutuellement inverses dans leur fonctionnement. Auteur : Tsvetkova A.V.
▪ Psychologie pédagogique. Notes de lecture ▪ Histoire de la psychologie. Lit de bébé
L'existence d'une règle d'entropie pour l'intrication quantique a été prouvée
09.05.2024 Mini climatiseur Sony Reon Pocket 5
09.05.2024 L'énergie de l'espace pour Starship
08.05.2024
▪ Bonne action ransomware virus ▪ Le risque d'infection dépend de l'heure de la journée ▪ Supercondensateurs VINATech VPC
▪ section du site Web de l'électricien. PUE. Sélection d'articles ▪ Article Pensée positive. Expression populaire ▪ article Connaissance pratique d'un microcircuit numérique. Radio - pour les débutants ▪ article Allumez le moteur triphasé. Encyclopédie de l'électronique radio et de l'électrotechnique
Page principale | bibliothèque | Articles | Plan du site | Avis sur le site
www.diagramme.com.ua |


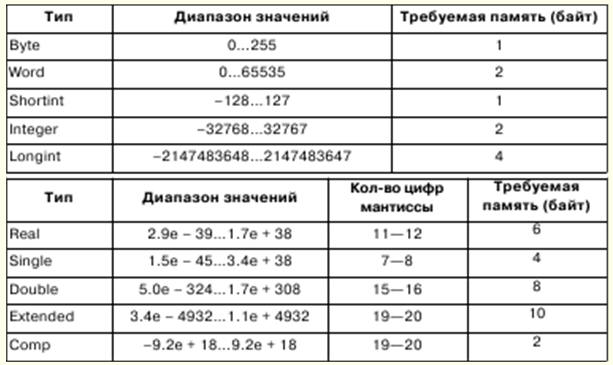

 Voir d'autres articles section
Voir d'autres articles section 